Đánh giá Dell PowerEdge R7725xd: định nghĩa giới hạn hiệu suất lưu trữ máy chủ 2u
Một số máy chủ mở rộng những gì đã tồn tại, trong khi những máy chủ khác tái định nghĩa lại các kỳ vọng. Dell PowerEdge R7725xd thuộc nhóm thứ hai. Trong đợt thử nghiệm gần đây của chúng tôi, với cấu hình gồm 24 ổ cứng SSD Micron 9550 PRO PCIe Gen5 NVMe và bốn card mạng (NIC) 2x 200GbE, máy chủ 2U này đã đạt được băng thông lưu trữ thô cao hơn bất kỳ hệ thống nào chúng tôi từng đo lường trước đây. Về mặt nội bộ, nền tảng này duy trì mức trên 300 GB/s trên toàn bộ nhóm ổ cứng NVMe. Qua mạng, nó truyền tải được 160 GB/s bằng giao thức RDMA tiêu chuẩn mà không cần thêm bất kỳ sự phức tạp nào.

Đây không chỉ đơn thuần là một máy chủ lưu trữ nhanh hơn, mà là một hệ thống thay đổi cách thiết kế kiến trúc điện toán chuyên dụng về dữ liệu (data-intensive computing). Các quy trình đào tạo và suy luận AI hiện đại thường bị giới hạn không phải bởi sức mạnh của GPU, mà bởi tốc độ chuẩn bị, truyền tải, xáo trộn và lưu dấu (checkpoint) dữ liệu. Các nút GPU lớn sẽ rơi vào trạng thái nhàn rỗi nếu lưu trữ không đáp ứng kịp. Các đội ngũ thường giải quyết những hạn chế này bằng cách sử dụng bộ nhớ đệm, tăng quy mô quá mức và phân tầng phức tạp để đảm bảo các bộ tăng tốc nhận dữ liệu đủ nhanh nhằm tối ưu hóa chi phí đầu tư.
Dell PowerEdge R7725xd giải quyết điểm nghẽn ngay tại nguồn. Máy chủ này được xây dựng trên bảng mạch kết nối (backplane) 24 khe cắm U.2, với mỗi ổ đĩa nhận một liên kết PCIe Gen5 x4 chuyên dụng trực tiếp đến phức hợp CPU AMD EPYC. Không có sự phân nhánh băng thông (bandwidth fan-out) và không sử dụng bộ mở rộng trung gian (midplane expander) để giảm tính đồng thời. Hiệu suất được mở rộng một cách mượt mà vì phần cứng được thiết kế để tổng hợp băng thông mà không gây xung đột. Trong cấu hình 2 socket truyền thống, các CPU được kết nối bằng 4 liên kết XGMI để giao tiếp nội bộ. Trên R7725xd, một trong các liên kết này được chuyển đổi mục đích để bổ sung thêm 16 làn PCIe Gen5 cho mỗi CPU, mang lại cho máy chủ tổng cộng 160 làn PCIe Gen5 (96 làn cho các ổ SSD phía trước và 64 làn cho bốn khe cắm PCIe phía sau). Khi kết hợp với ổ cứng SSD Micron 9550 PRO — vốn được thiết kế cho các tác vụ ghi duy trì và độ bền cao — hệ thống sẽ trở thành một “động cơ dữ liệu” băng thông cao, có khả năng hỗ trợ các tác vụ ghi dấu (checkpoint) liên tục và truyền tải dữ liệu không ngừng.
Chúng tôi đã triển khai PEAK: AIO trên nền tảng kiến trúc này để tận dụng các đường dẫn gửi dữ liệu song song và duy trì hiệu quả khi tính đồng thời tăng lên. Kết quả thu được không chỉ là hiệu suất đỉnh cao mà còn là hiệu suất duy trì ổn định dưới tải nặng. Nền tảng này có thể vận hành như một nút thực thi cục bộ cho việc tiền xử lý, đào tạo hoặc chuyển đổi dữ liệu, hoặc nó có thể cung cấp lưu trữ băng thông cao cho nhiều hệ thống GPU thông qua mạng lưới. Nếu muốn thử thách hơn, bạn hoàn toàn có thể thực hiện cả hai việc này cùng một lúc.
Những điểm chính (Key Takeaways) :
- Băng thông chưa từng có trên một nút đơn lẻ: R7725xd duy trì băng thông nội bộ hơn 300 GB/s và 160 GB/s qua NVMe-oF RDMA, cạnh tranh trực tiếp với các cụm lưu trữ đa nút chỉ trong một khung máy 2U.
- Kiến trúc Gen5 thực thụ, không bộ chuyển mạch, không phân nhánh: Tất cả 24 ổ SSD Micron 9550 PRO đều nhận các làn PCIe Gen5 x4 chuyên dụng trực tiếp từ phức hợp CPU, cho phép mở rộng tốc độ đường truyền (line-rate) mà không gây xung đột.
- Sức mạnh từ dòng AMD EPYC 9005: Bộ đôi vi xử lý AMD EPYC 9575F cung cấp số lượng làn PCIe, băng thông bộ nhớ và cấu trúc liên kết NUMA cần thiết để duy trì I/O với tính đồng thời cao.
- Thiết kế cho AI, Phân tích và các tác vụ nặng về ghi dấu (Checkpoint): Hệ thống loại bỏ các điểm nghẽn I/O vốn thường làm đình trệ các quy trình GPU hiện đại, cho phép truyền tải dữ liệu băng thông cao liên tục.
- PEAK: AIO khai phá toàn bộ tính song song: Ngăn xếp phần mềm của PEAK: AIO giữ cho các cấu trúc hàng đợi luôn bão hòa dưới tải nặng, mang lại hiệu suất doanh nghiệp với tỷ lệ chi phí trên mỗi GB (dollar-per-GB) cực kỳ hấp dẫn.
Thiết kế chuyên biệt cho băng thông NVMe
Trong các dòng máy chủ mới nhất, Dell đã dần loại bỏ việc sử dụng các bộ chuyển mạch PCIe (PCIe switches) trong các cấu hình máy chủ có mật độ lưu trữ cao. Các mẫu như PowerEdge R770 hoặc R7725 cung cấp các khe cắm PCIe Gen5 x4 hỗ trợ cấu hình lên đến 16 ổ SSD, và chuyển sang các khe cắm x2 trong các cấu hình bảng mạch kết nối lưu trữ lớn hơn. Các máy chủ thế hệ trước, chẳng hạn như PowerEdge R760, thường bao gồm một bộ chuyển mạch PCIe trong các cấu hình NVMe 24 khe cắm. Để đơn giản hóa việc lắp đặt và loại bỏ sự phức tạp do bộ chuyển mạch PCIe gây ra, các máy chủ mới đã áp dụng chiến lược giảm số lượng làn PCIe trong các phiên bản có mật độ lưu trữ dày đặc. Tuy nhiên, điều đó đã thay đổi với R7725xd.
Sự khác biệt giữa bản R7725 tiêu chuẩn và R7725xd nằm ở cách nền tảng phân bổ tài nguyên PCIe root complex. Phiên bản R7725 cơ bản phân phối các làn PCIe cho lưu trữ, mở rộng GPU và I/O mục đích chung. Biến thể ‘xd’ phân bổ lại nguồn tài nguyên đó để hệ thống phụ NVMe trở thành đối tượng tiêu thụ băng thông PCIe chính. 24 khe cắm U.2 được kết nối trực tiếp vào các cổng gốc (roots) PCIe Gen5 của CPU, với mỗi ổ SSD nhận một điểm cuối (endpoint) x4 riêng biệt, thay vì một đường truyền lên (uplink) dùng chung thông qua bộ chuyển mạch PCIe hoặc cây định thì lại (re-timer tree). Điều này cung cấp cho mỗi ổ đĩa các cấu trúc hàng đợi độc lập và các đường dẫn DMA độc lập quay trở lại bộ điều khiển bộ nhớ.

Cấu trúc bảng mạch kết nối (backplane) và riser phản ánh rõ nét cam kết này. Dell phân nhóm các đầu nối NVMe và khe cắm PCIe trên cả hai socket AMD EPYC, nhờ đó mỗi bộ vi xử lý trực tiếp sở hữu một phần của tập hợp ổ đĩa. Trên thực tế, điều này tạo ra hai miền NVMe đối xứng, mỗi miền có các đặc tính trễ cục bộ và khả năng đọc/ghi đồng thời toàn diện. Khi chúng tôi lắp đặt bốn card mạng (NIC) Broadcom cổng kép 200GbE dưới dạng card rời, việc sắp xếp vị trí khe cắm cho phép mỗi NIC nằm trong một miền PCIe tương ứng với nhóm NVMe liên quan. Với giao thức NVMe-over-RDMA, điều này có nghĩa là lưu lượng mạng được giữ cục bộ tại socket đang xử lý I/O của ổ đĩa tương ứng, tránh việc dữ liệu phải nhảy qua cầu nối Infinity Fabric giữa các socket – vốn là yếu tố thường làm tăng độ trễ và tiêu tốn băng thông khi tải nặng.
Đặc tính nhiệt học cũng hỗ trợ duy trì băng thông ổn định. Chuẩn U.2 vẫn giữ được lợi thế trong các cấu hình Gen5 mật độ cao vì nó cung cấp kênh luồng khí xác định và diện tích bề mặt tản nhiệt có thể dự đoán được cho mỗi thiết bị. Các mô-đun quạt áp suất tĩnh cao và hệ thống ống dẫn trong khung máy của R7725xd duy trì luồng không khí ổn định trên cả 24 khe cắm, cho phép các tác vụ ghi toàn bộ ổ đĩa chạy liên tục mà không bị hạ xung do quá nhiệt (throttling). Thiết kế cơ khí bổ trợ hoàn hảo cho thiết kế điện tử: mỗi ổ đĩa có thể duy trì hiệu suất tối đa vì nền tảng này được chế tạo để làm mát đồng thời 24 thiết bị Gen5 khi đang hoạt động hết công suất.
Sự kết hợp giữa việc căn chỉnh cổng gốc (root-complex), bố cục làn truy cập bộ nhớ không đồng nhất (NUMA) nhất quán, vị trí card mạng nhận biết socket và đóng gói U.2 ổn định về nhiệt đã cho phép hệ thống đạt được tốc độ I/O tối đa theo đường truyền ở quy mô lớn. Kiến trúc này giúp tránh được các điểm nghẽn và tối ưu hóa hiệu suất một cách triệt để.
Tổng quan về Dell PowerEdge R7725xd iDRAC 10
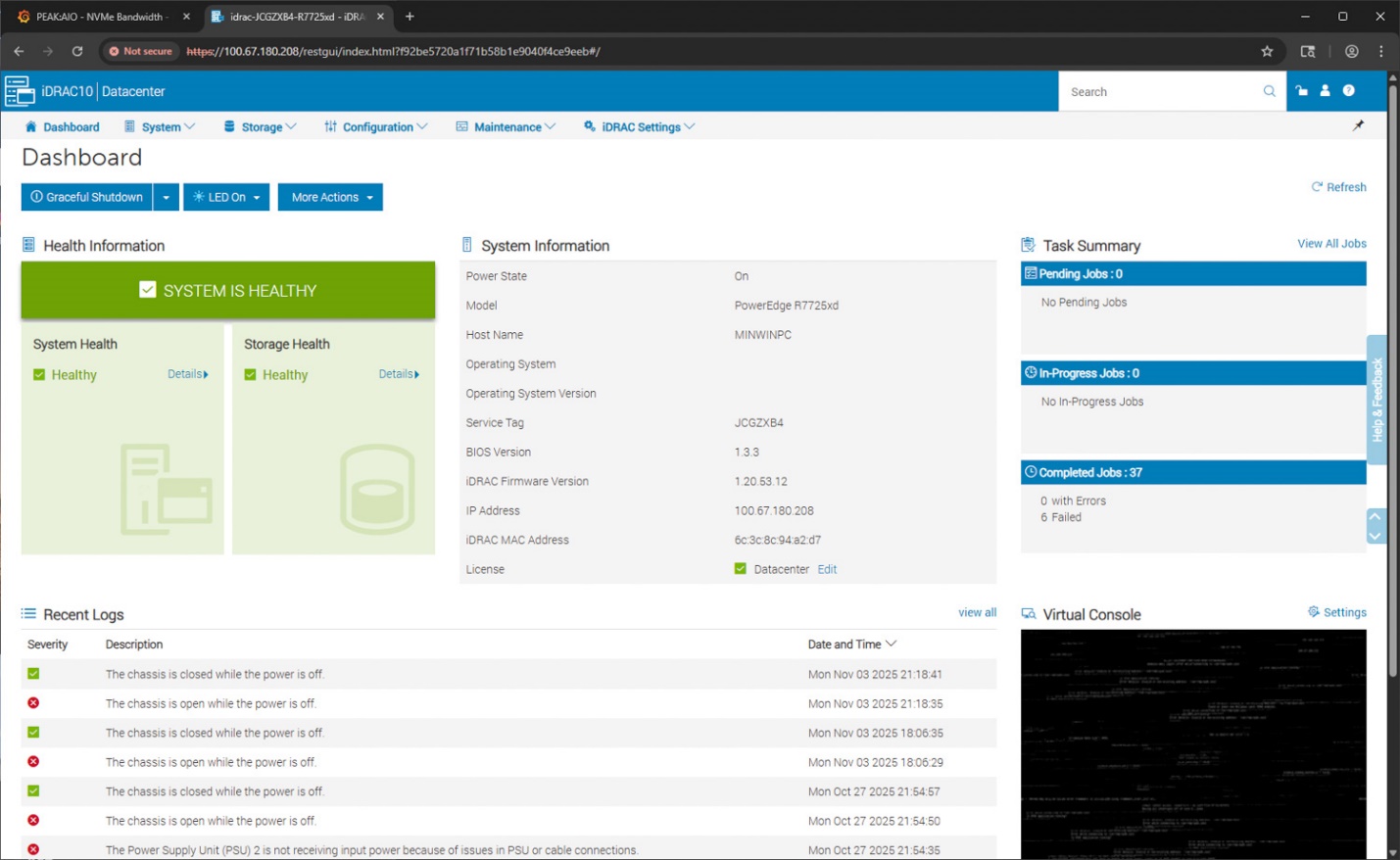
Thế hệ R7725xd này, cũng giống như nhiều nền tảng thế hệ thứ 17 khác mà chúng tôi đã đánh giá, sở hữu nền tảng iDRAC 10 mới của Dell. Đây là điểm trung tâm cho việc quản lý từ xa, theo dõi sức khỏe hệ thống và điều khiển ngoài băng tần (out-of-band). Giao diện bảng điều khiển (dashboard) cung cấp bản tóm tắt tức thì về tình trạng tổng thể của hệ thống, trạng thái lưu trữ và các hoạt động gần đây. Đối với thiết bị thử nghiệm của chúng tôi, báo cáo sức khỏe hệ thống và lưu trữ hiển thị màu xanh, xác nhận máy chủ đang hoạt động bình thường. Các chi tiết chính của hệ thống như kiểu máy (model), tên máy chủ (hostname), phiên bản BIOS, cấp độ phần sụn (firmware) iDRAC, địa chỉ IP và thông tin bản quyền được hiển thị ở phía bên phải của giao diện.
Bảng điều khiển cũng bao gồm một bảng tóm tắt tác vụ, hiển thị các hoạt động đã hoàn thành, đang chờ xử lý và đang thực hiện. Phía dưới đó là danh sách các nhật ký (logs) gần đây ghi lại các sự kiện xâm nhập khung máy và thông điệp từ bộ nguồn, giúp hiểu nhanh các thay đổi trạng thái phần cứng mà không cần phải điều hướng vào các menu sâu hơn. Bảng điều khiển ảo (virtual console) nằm ở góc dưới cùng bên phải để thực hiện quyền điều khiển KVM từ xa toàn diện.
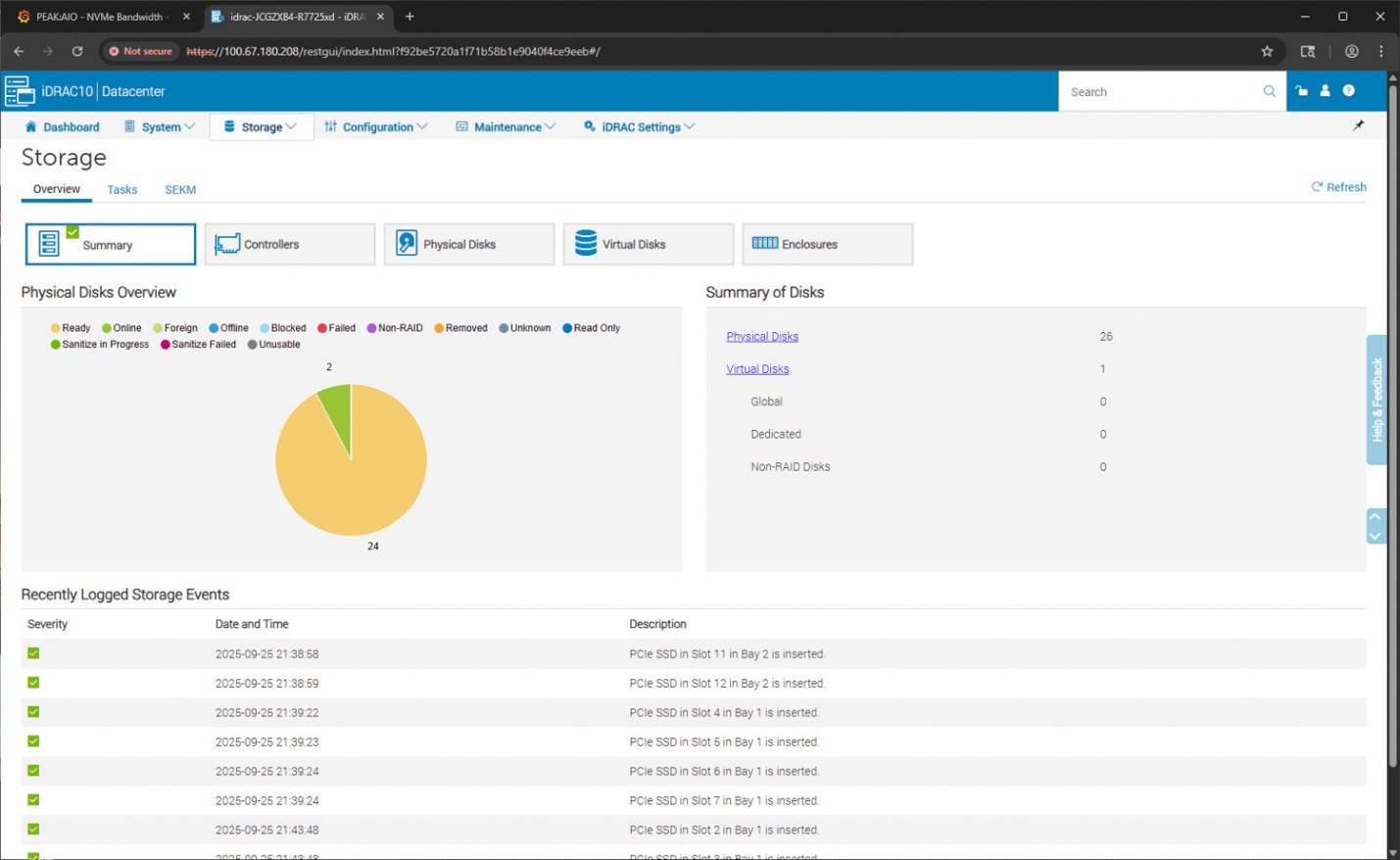
Phần lưu trữ của iDRAC 10 trình bày một cái nhìn tổng thể đầy đủ về tất cả các đĩa vật lý được lắp đặt trong R7725xd. Bảng tóm tắt hiển thị số lượng tổng quát của tất cả các ổ đĩa đã kết nối, đi kèm với một biểu đồ tròn trực quan minh họa trạng thái của các ổ đĩa đó. Trong cấu hình này, 24 ổ SSD NVMe đang hoạt động và báo trạng thái sẵn sàng, cùng với hai thiết bị khởi động bổ sung có mặt trong hệ thống, tách biệt với dãy NVMe chính phía trước.
Ở bên phải, bảng Tóm tắt đĩa (Summary of Disks) chia nhỏ các thiết bị này thành đĩa vật lý và bất kỳ đĩa ảo liên quan nào. Vì R7725xd sử dụng kiến trúc NVMe trực tiếp mà không có bộ điều khiển RAID truyền thống, tất cả các ổ đĩa đều được báo cáo là Non-RAID và có thể định địa chỉ riêng lẻ, phù hợp với thiết kế của hệ thống dành cho các nhóm NVMe lớn và nền tảng SDS (lưu trữ định nghĩa bằng phần mềm).
Phía dưới phần tóm tắt trạng thái, khu vực Các sự kiện lưu trữ được ghi nhật ký gần đây (Recently Logged Storage Events) liệt kê nhật ký nạp ổ cho từng ổ SSD PCIe, được sắp xếp theo ngăn (bay) và khe cắm (slot). Bản ghi này xác nhận việc nhận diện chính xác trên tất cả các ngăn ổ đĩa và giúp xác định bất kỳ vấn đề nào liên quan đến việc lắp đặt, đi dây hoặc hoạt động cắm nóng (hot-swap). Đối với các đợt triển khai lớn, những nhật ký này rất hữu ích khi theo dõi việc cấp phát ổ đĩa hoặc xác nhận rằng dung lượng đã được lấp đầy đúng như mong đợi.
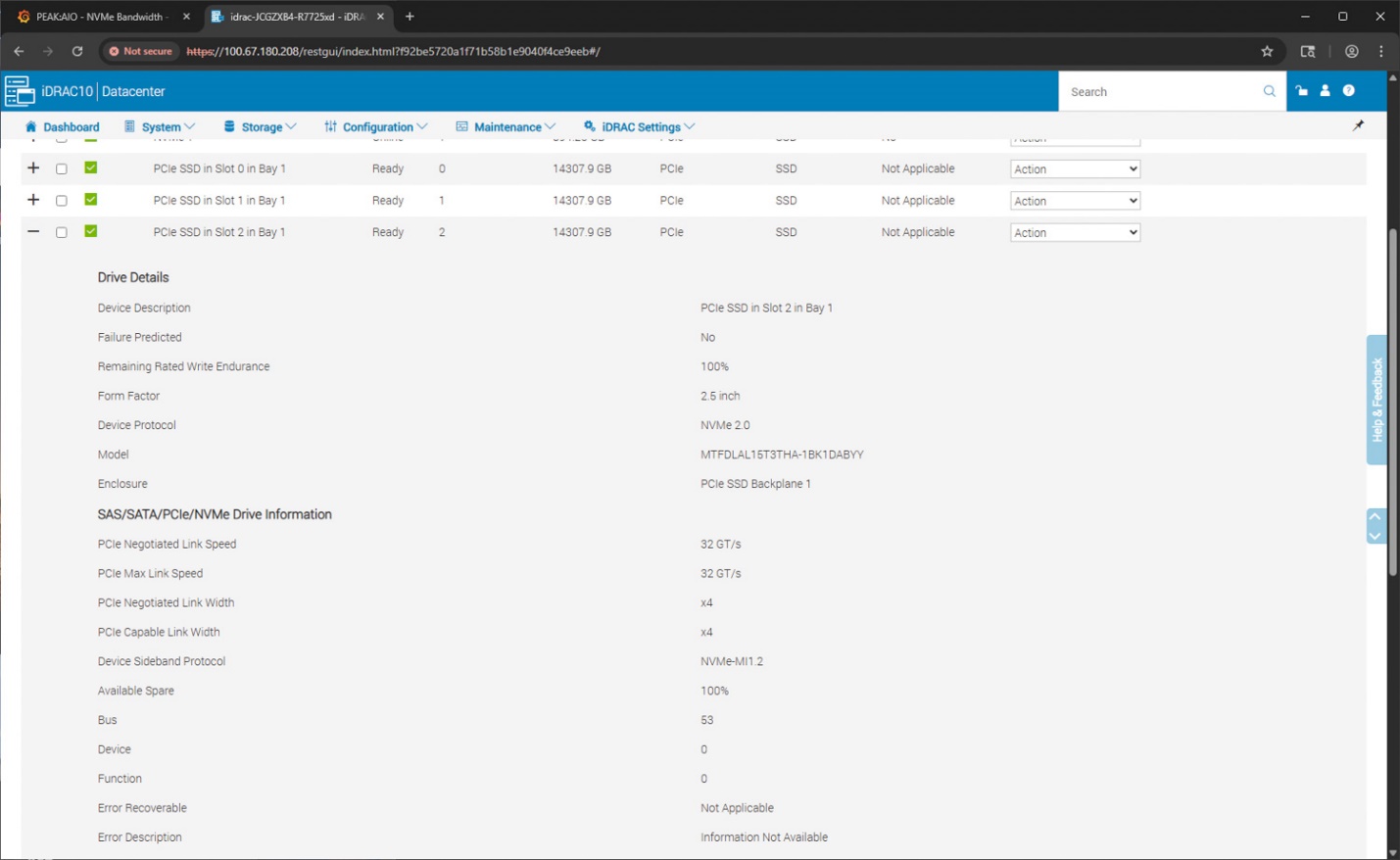
Ảnh chụp màn hình cuối cùng hiển thị chế độ xem chi tiết thiết bị NVMe trong iDRAC 10. Mỗi ổ cứng NVMe được lắp đặt trong hệ thống đều được liệt kê cùng với trạng thái, dung lượng và vị trí ngăn ổ đĩa. Việc chọn một ổ đĩa riêng lẻ sẽ mở ra bảng phân tích đầy đủ về các đặc tính của nó.
Trong ví dụ này, bảng thông tin ổ đĩa hiển thị đầy đủ chuỗi ký tự kiểu máy (model), giao thức thiết bị, hệ số hình dạng (form factor) và các thiết lập PCIe đã thiết lập. Các thiết bị NVMe đang chạy ở tốc độ liên kết 32 GT/s với kết nối x4 đã thiết lập, xác nhận rằng các ổ đĩa đang hoạt động ở băng thông tối đa trên bảng mạch kết nối PCIe Gen5 của hệ thống. Phần thông tin cũng báo cáo phần trăm độ bền, trạng thái dự phòng còn lại và loại giao thức, giúp quản trị viên theo dõi sức khỏe ổ đĩa và dự đoán vòng đời sử dụng.
Việc báo cáo chi tiết ổ đĩa này rất có giá trị trong các cấu hình NVMe mật độ cao, nơi mà độ rộng liên kết, tốc độ thiết lập và sức khỏe của phương tiện lưu trữ ảnh hưởng trực tiếp đến hành vi của khối lượng công việc và hiệu suất lưu trữ.
Nhìn chung, giao diện iDRAC 10 cung cấp một cái nhìn rõ ràng, tập trung vào phần cứng về kiến trúc lưu trữ NVMe của R7725xd, cho phép dễ dàng kiểm chứng tình trạng liên kết, trạng thái ổ đĩa và tính toàn vẹn của hệ thống chỉ trong nháy mắt.
Hiệu năng Dell PowerEdge R7725xd
Trước khi tiến hành thử nghiệm, hệ thống của chúng tôi đã được cấu hình với các thành phần cân bằng nhưng có hiệu suất cực cao. Hệ thống được trang bị hai bộ vi xử lý AMD EPYC 9575F, mỗi bộ có 64 nhân tần số cao, đi kèm với 24 thanh RAM DDR5 DIMM dung lượng 32GB hoạt động ở tốc độ 6400 MT/s. Về lưu trữ, khung máy được lấp đầy bởi 24 ổ SSD Micron 9550 PRO U.2 NVMe dung lượng 15,36TB, mỗi ổ được kết nối thông qua một liên kết PCIe Gen5 x4 chuyên dụng. Cấu hình này cung cấp tổng dung lượng thô là 368,64 TB; các ổ Micron 9550 PRO này đạt tốc độ đọc tuần tự lên đến 14.000 MB/s và tốc độ ghi tuần tự lên đến 10.000 MB/s. Về kết nối mạng, hệ thống sử dụng bốn bộ chuyển đổi Broadcom BCM57608 cung cấp tổng cộng tám cổng 200Gb, cùng với một card mạng BCM57412 OCP NIC cung cấp thêm hai cổng 10 gigabit.

Test System Specifications
- CPU: 2x AMD EPYC 9575F 64-Core High-Frequency Processors
- Memory: 24x 32GB DDR5 @ 6400MT/s
- Storage: 24x 15.36TB Micron 9550 PRO U.2 drives (connected at 4x lanes of PCIe Gen5 each); supports up to 128TB drives today with higher capacities on the horizon
- Network: 4x Broadcom BCM57608 2x200G NICs, 1x BCM57412 2x10Gb OCP NIC
- Switch: Dell PowerSwitch Z9664
Kiểm thử hiệu năng với FIO
Để đo lường hiệu suất lưu trữ của PowerEdge R7725xd, chúng tôi đã sử dụng các tiêu chuẩn đo lường của ngành và công cụ FIO. Trong phần này, chúng tôi tập trung vào các bài kiểm tra FIO sau đây:
- Random 4K – 1M
- Sequential 4K – 1M

FIO – Cục bộ – Băng thông
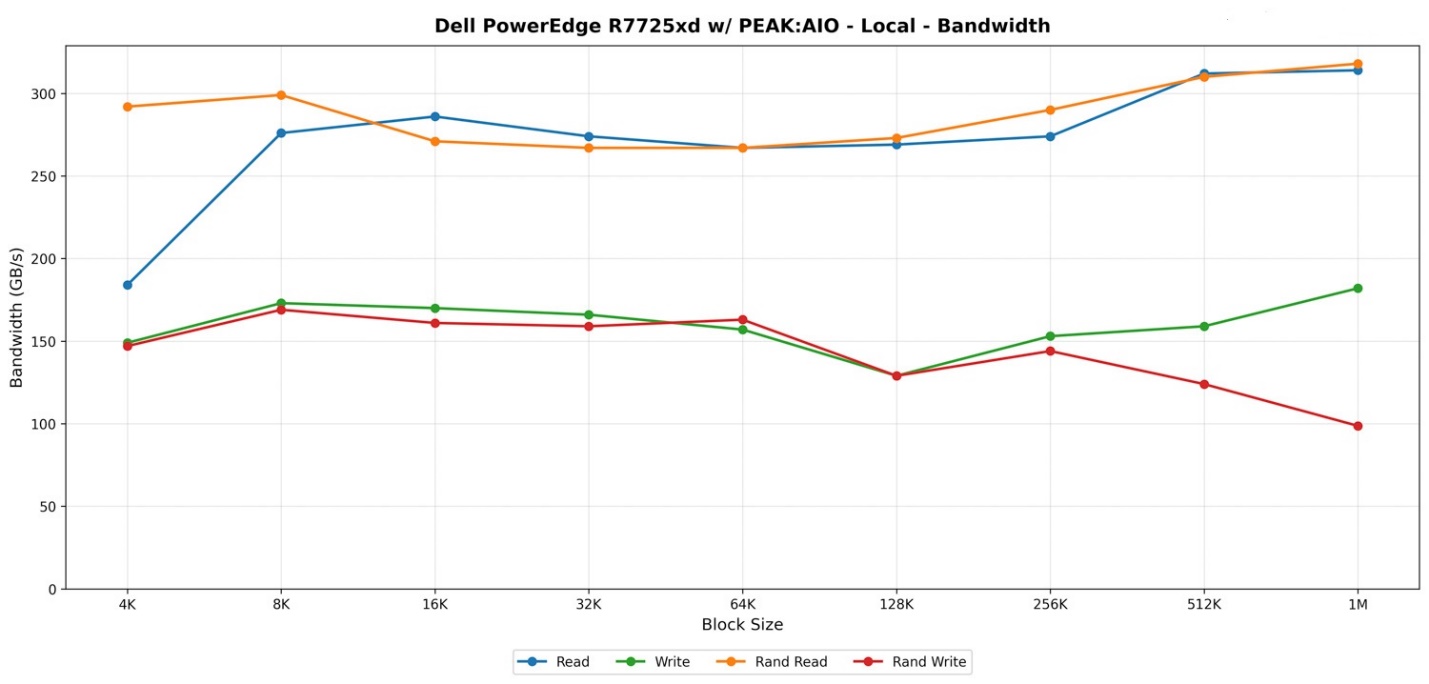
Khi thử nghiệm truy cập cục bộ vào 24 ổ đĩa PCIe Gen5 NVMe bên trong Dell PowerEdge R7725xd, hệ thống thể hiện chính xác những gì bạn mong đợi từ một nền tảng mà mọi ổ đĩa đều được kết nối với CPU bằng liên kết PCIe Gen5 x4 đầy đủ. Khi không có lớp mạng tham gia, đây là băng thông nội bộ thuần túy của bố cục lưu trữ Gen5 từ Dell và băng thông PCIe của nền tảng AMD EPYC hoạt động mà không bị hạn chế.
Đọc tuần tự (Sequential Read) bắt đầu ở mức 184 GB/s với các khối dữ liệu (block size) 4K và tăng nhanh khi kích thước khối tăng lên. Từ mức 512K đến 1M, máy chủ duy trì ổn định ở mức 312 đến 314 GB/s, một minh chứng rõ nét cho khả năng tổng hợp tất cả 24 × 4 làn Gen5 thành băng thông đọc duy trì mà không gặp bất kỳ điểm nghẽn nào ở giai đoạn điều khiển.
Ghi tuần tự (Sequential Write) đi theo một lộ trình khác nhưng vẫn nằm chắc chắn trong phạm vi kỳ vọng. Bắt đầu ở mức 149 GB/s, kết quả tăng dần qua ngưỡng giữa 100 và đạt 182 GB/s ở kích thước khối 1M. Điều này phù hợp với đặc tính ghi của ổ SSD Micron 9550 PRO và mức tiêu hao tài nguyên (overhead) vốn có của các tác vụ ghi NVMe song song cao trên nhiều thiết bị độc lập như vậy.
Hiệu suất đọc ngẫu nhiên (Random Read) là một điểm sáng khác. Hệ thống đạt tốc độ gần 300 GB/s ở các kích thước khối nhỏ nhất, giảm nhẹ ở mức tầm trung, sau đó phục hồi lên mức trên 200 và đạt ngưỡng 300 thấp ở các kích thước khối lớn hơn. Tại mức 1M, tốc độ đọc ngẫu nhiên đạt tối đa 318 GB/s, chứng minh khả năng của nền tảng trong việc phân phối các hoạt động hỗn hợp đồng đều trên cả 24 ổ đĩa.
Ghi ngẫu nhiên (Random Write) đạt tốc độ thấp hơn, đây là điều điển hình đối với các tác vụ phân tán siêu dữ liệu (metadata) và cấp phát ghi trên một tập hợp NVMe rộng lớn. Kết quả duy trì trong khoảng từ 140 đến 160 GB/s trong hầu hết các bài kiểm tra và giảm xuống mức dưới 100 GB/s tại kích thước khối 1M.
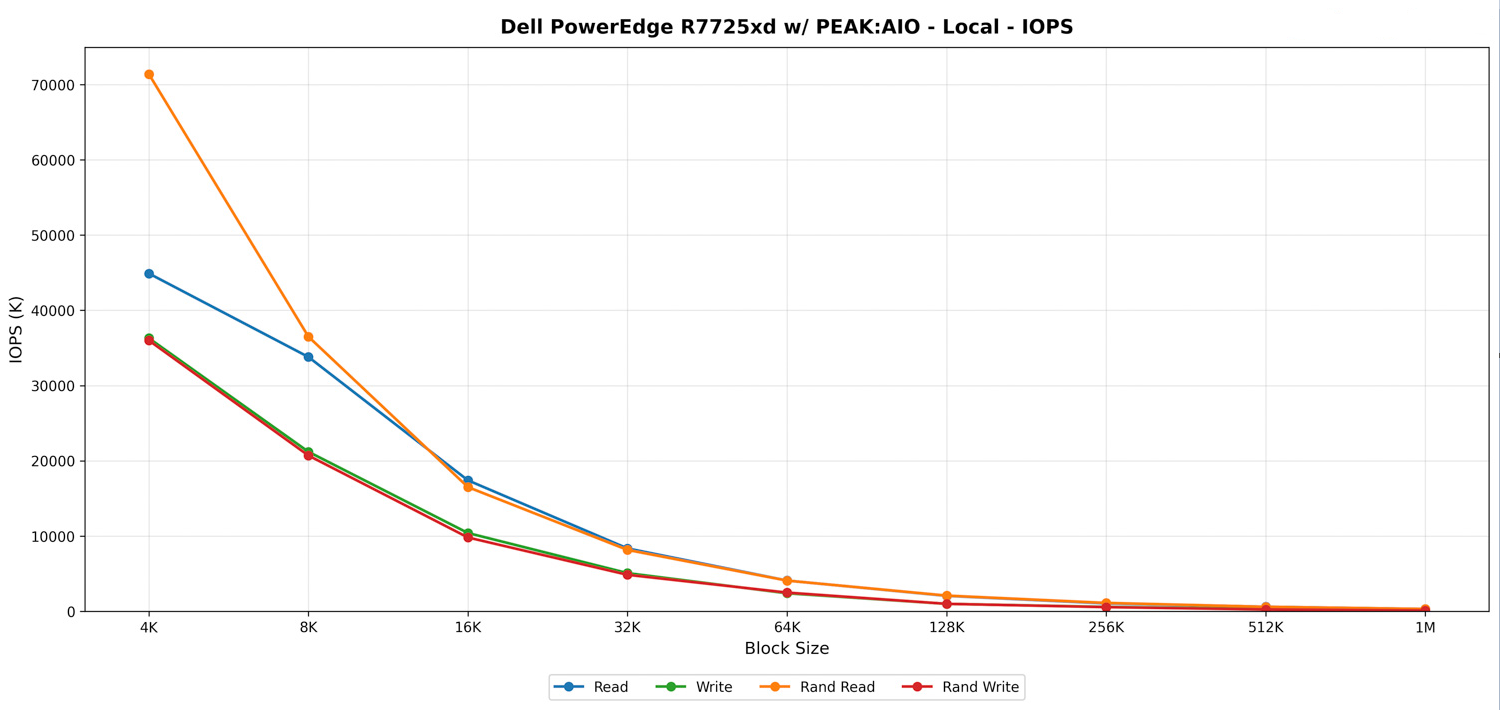
FIO – Cục bộ – IOPS
Khi xem xét về khía cạnh IOPS, R7725xd thể hiện hiệu suất mạnh mẽ với các khối dữ liệu nhỏ, với tốc độ yêu cầu đạt tới hàng chục triệu trước khi các kích thước khối lớn hơn chuyển khối lượng công việc sang cấu hình thiên về băng thông.
Tại mức 4K, tốc độ đọc đạt 44,9 triệu IOPS và tốc độ ghi đạt 36,3 triệu IOPS. Đọc ngẫu nhiên thậm chí còn đạt mức cao hơn với 71,4 triệu IOPS, chứng minh khả năng của hệ thống trong việc phân phối hiệu quả các khối lượng công việc có hàng đợi cao (high-queue) trên tất cả các ổ đĩa. Các giá trị này giảm dần một cách tự nhiên khi kích thước khối tăng lên, nhưng tiến trình này vẫn duy trì sự nhất quán qua các dải 8K, 16K và 32K.
Đến các khối 16K và 32K, tốc độ đọc ổn định ở mức 17,4 triệu và 8,35 triệu IOPS, với tốc độ đọc ngẫu nhiên tương ứng gần như khớp ở mức 16,5 triệu và 8,15 triệu IOPS. Tốc độ ghi tuân theo quy luật dự kiến, ở mức thấp hơn nhưng vẫn duy trì ổn định trên cả các kiểu truy cập tuần tự và ngẫu nhiên.
Khi chúng ta chuyển sang mức 64K và cao hơn, bài kiểm tra chuyển đổi từ IOPS thuần túy sang kịch bản bị giới hạn bởi băng thông. Chỉ số IOPS rơi xuống phạm vi vài triệu và cuối cùng là hàng trăm nghìn. Tại kích thước khối 1M, IOPS đọc đạt khoảng 300K, ghi khoảng 174K, và các hoạt động ngẫu nhiên cũng kết thúc ở mức tương đương.
Nhìn chung, kết quả IOPS cục bộ cho thấy rõ khả năng của hệ thống trong việc duy trì khối lượng công việc có độ sâu hàng đợi (queue-depth) rất cao trên các khối dữ liệu nhỏ, với khả năng mở rộng có thể dự đoán được khi dung lượng truyền tải lớn dần và băng thông trở thành yếu tố chi phối.
PEAK:AIO: Tại sao Dell PowerEdge R7725xd lại phù hợp với khối lượng công việc này
PEAK:AIO được thiết kế cho các môi trường đòi hỏi khả năng truy cập cực nhanh và độ trễ thấp vào các tập dữ liệu lớn, điển hình là đào tạo AI, quy trình suy luận, mô hình hóa tài chính và phân tích thời gian thực. Nền tảng này phát huy tối đa sức mạnh trên các hệ thống lưu trữ NVMe mật độ cao, băng thông PCIe cân bằng và độ trễ có thể dự đoán được ở quy mô lớn. Để đáp ứng các yêu cầu này, phần cứng bên dưới phải cung cấp băng thông duy trì trong khi vẫn giữ được hiệu suất nhất quán và có khả năng lặp lại dưới các mức tải nặng đồng thời.
Đây chính là điểm mà Dell PowerEdge R7725xd tương thích một cách tự nhiên với PEAK:AIO. Kiến trúc của hệ thống được thiết kế để tối đa hóa tài nguyên PCIe Gen5, phơi bày toàn bộ băng thông của 24 ngăn ổ đĩa U.2 NVMe phía trước trực tiếp tới các CPU mà không cần phụ thuộc vào bộ điều khiển RAID truyền thống. Bố cục này cung cấp cho PEAK:AIO tính song song và cấu hình độ trễ mà nó mong đợi từ các quy trình dữ liệu dựa trên NVMe hiện đại. Cấu hình hệ thống đã chia các ổ SSD NVMe thành hai nhóm RAID0.

Trong thử nghiệm, chúng tôi đã sử dụng hai hệ thống máy khách (client) kết nối với R7725xd, mỗi hệ thống được trang bị card mạng Broadcom BCM57608 2x 200G. Thiết lập này tạo ra tổng cộng bốn đường truyền lên (uplink) 200G cung cấp dữ liệu cho mỗi máy khách, đưa R7725xd vào một cấu hình hiệu suất cao thực tế, mô phỏng đúng những gì các đợt triển khai PEAK:AIO gặp phải trong môi trường vận hành thực tế. Mức băng thông mạng này đã tạo ra khoảng trống (headroom) cần thiết để chúng tôi có thể gây áp lực tối đa lên hệ thống phụ NVMe, cấu trúc liên kết PCIe và các kết nối liên CPU mà không bị nghẽn ở lớp card mạng.
Kết quả là một nền tảng liên kết hiệu quả với các khối lượng công việc của PEAK:AIO. R7725xd cung cấp dung lượng NVMe mật độ cao, băng thông PCIe Gen5, bộ đôi vi xử lý AMD EPYC 9005 cho tính song song, và khả năng kết nối mạng để duy trì việc nạp dữ liệu đa máy khách ở mức hàng trăm gigabit trên mỗi máy khách. Tất cả những đặc tính này là nền tảng cốt lõi để đạt được các kỳ vọng về hiệu suất của PEAK:AIO.
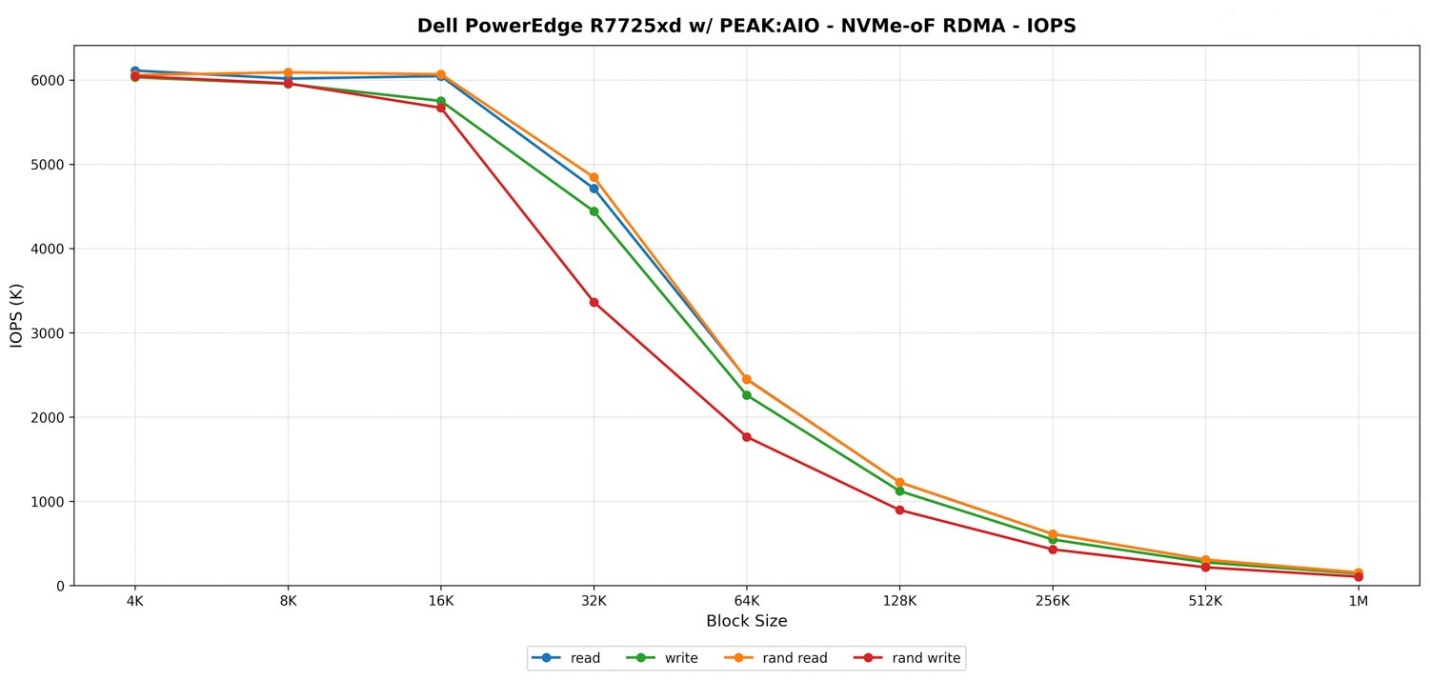
PEAK:AIO – NVMe-oF RDMA – Băng thông
Khi xem xét các kết quả băng thông NVMe-oF RDMA trên PowerEdge R7725xd kết hợp với PEAK:AIO, xu hướng tổng thể chính xác là những gì chúng tôi kỳ vọng từ một hệ thống có băng thông PCIe và mạng lớn như thế này. Khi kích thước khối tăng lên, băng thông tăng nhanh cho đến khi đạt mức ổn định gần giới hạn thực tế của nền tảng.
Ở các kích thước khối nhỏ, hiệu suất bắt đầu trong khoảng giữa 20 GB/s cho cả đọc và ghi, điều này là bình thường vì các lần truyền tải 4K và 8K gây áp lực lên đường dẫn IOPS mạnh hơn nhiều so với đường dẫn băng thông. Một khi chúng ta đạt đến các khối 16K và 32K, đường truyền bắt đầu khai mở. Tốc độ đọc nhảy vọt lên khoảng 154 GB/s tại mức 32K và tiếp tục leo lên phạm vi 160 GB/s, đây chính là mức mà chúng tôi dự đoán cho một thiết lập hai máy khách qua bốn liên kết 200 Gb/s.
Hiệu suất đọc ngẫu nhiên phản chiếu gần như hoàn hảo so với đọc tuần tự. PEAK:AIO đã thực hiện rất tốt việc duy trì các hàng đợi lệnh luôn đầy, vì vậy băng thông đọc ngẫu nhiên về cơ bản bám sát băng thông đọc tuần tự trong suốt quá trình, ổn định ở mức xấp xỉ 159 đến 161 GB/s từ mức 32K đến 1M. Điều này cho thấy ngăn xếp lưu trữ không bị nghẽn dưới các kiểu truy cập hỗn hợp, và cấu trúc liên kết PCIe của R7725xd đang phân phối tải đều trên cả 24 ổ NVMe Gen5.
Hiệu suất ghi cũng tuân theo một biểu đồ tương tự, mặc dù đạt đỉnh thấp hơn một chút so với đọc. Ghi tuần tự duy trì trong khoảng 140 đến 148 GB/s qua các khối kích thước trung bình, giảm xuống xấp xỉ 117 GB/s tại mức 128K nhưng phục hồi khi kích thước khối tăng lên. Ghi ngẫu nhiên diễn biến khác biệt và đi ngang ở mức gần 110-117 GB/s, đây là điều bình thường đối với các khối lượng công việc hàng đợi hỗn hợp vốn phát sinh thêm chi phí tài nguyên (overhead).
Điểm mấu chốt rút ra từ phần này là R7725xd không gặp khó khăn gì trong việc duy trì băng thông cực cao qua NVMe-oF, ngay cả khi có nhiều máy khách thúc đẩy hệ thống đến các giới hạn của nó. Một khi kích thước khối đạt đến 32K hoặc cao hơn, máy chủ liên tục làm bão hòa băng thông mạng và lưu trữ sẵn có. Đây chính xác là loại hiệu suất mà PEAK:AIO được thiết kế để khai thác, khiến các kết quả này trở thành một minh chứng mạnh mẽ cho khả năng mở rộng của nền tảng trong các điều kiện thực tế.
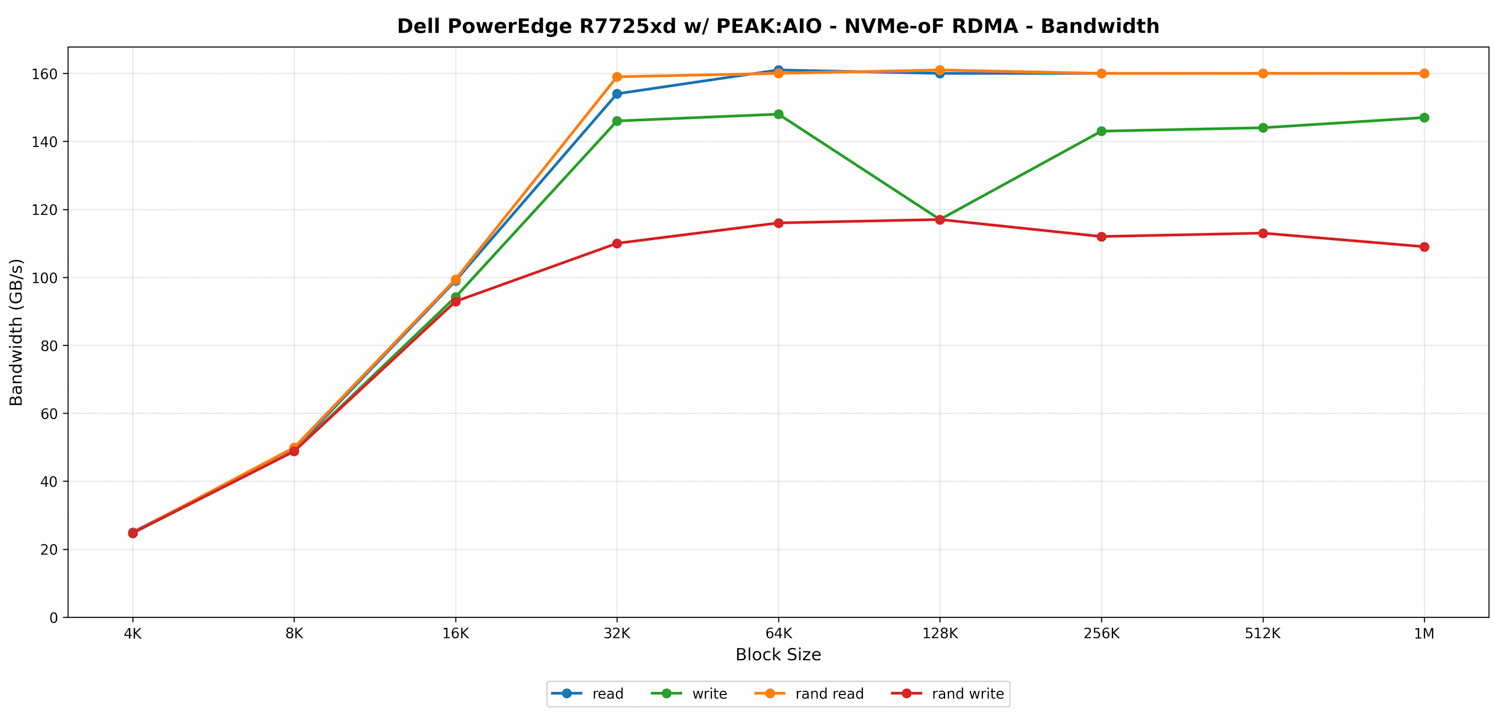
PEAK:AIO – NVMe-oF RDMA IOPS
Về khía cạnh IOPS, PowerEdge R7725xd thể hiện hiệu suất mạnh mẽ với các khối dữ liệu nhỏ, mặc dù ban đầu chúng tôi quan sát thấy các con số thấp hơn kỳ vọng; vấn đề này dự kiến sẽ được giải quyết bằng việc cải thiện hỗ trợ trình điều khiển mạng trong tương lai. Ngay cả khi xét đến yếu tố đó, xu hướng mở rộng tổng thể vẫn diễn ra chính xác như cách NVMe-oF RDMA thường vận hành khi kích thước khối tăng lên.
Ở kích thước khối nhỏ nhất, hệ thống có thể cung cấp hơn 6 triệu IOPS cho cả khối lượng công việc tuần tự và ngẫu nhiên. Các chỉ số đọc, ghi, đọc ngẫu nhiên và ghi ngẫu nhiên đều nằm trong cùng một khoảng tại mức 4K và 8K, cho thấy các máy khách đầu cuối, hạ tầng PCIe và bản thân các ổ cứng NVMe không gặp khó khăn gì trong việc đáp ứng tốc độ yêu cầu.
Khi kích thước khối tăng lên, sự sụt giảm IOPS theo dự kiến bắt đầu xuất hiện. Tại mức 32K, tốc độ đọc đạt khoảng 4,7 triệu IOPS, trong khi tốc độ ghi thấp hơn một chút ở mức khoảng 4,4 triệu. Ghi ngẫu nhiên chịu ảnh hưởng lớn nhất ở giai đoạn này, giảm xuống còn khoảng 3,3 triệu IOPS, phù hợp với việc phát sinh thêm hàng đợi và chi phí tài nguyên CPU do các kiểu truy cập hỗn hợp gây ra.
Chuyển sang các khối dữ liệu lớn, IOPS tiếp tục giảm dần theo một đường tuyến tính có thể dự đoán được. Đến khi đạt tới các lần truyền tải 256K và 512K, băng thông trở thành thước đo chủ đạo và IOPS giảm xuống mức vài trăm nghìn một cách tự nhiên. Tại kích thước khối 1M, tất cả các khối lượng công việc hội tụ về mức 140K – 153K IOPS, nhất quán với các số liệu băng thông mà chúng tôi đã thấy ở phần trước.
Hiệu suất GPUDirect Storage
Một trong những bài kiểm tra chúng tôi đã thực hiện trên R7725xd là bài thử nghiệm Magnum IO GPUDirect Storage (GDS). GDS là một tính năng được phát triển bởi NVIDIA, cho phép các GPU bỏ qua CPU khi truy cập dữ liệu được lưu trữ trên ổ cứng NVMe hoặc các thiết bị lưu trữ tốc độ cao khác. Thay vì định tuyến dữ liệu thông qua CPU và bộ nhớ hệ thống, GDS cho phép giao tiếp trực tiếp giữa GPU và thiết bị lưu trữ, giúp giảm đáng kể độ trễ và cải thiện băng thông dữ liệu.
Cách thức hoạt động của GPUDirect Storage
Theo cách truyền thống, khi một GPU xử lý dữ liệu được lưu trữ trên ổ NVMe, dữ liệu trước tiên phải đi qua CPU và bộ nhớ hệ thống trước khi đến được GPU. Quá trình này tạo ra các điểm nghẽn vì CPU trở thành “người trung gian”, làm tăng độ trễ và tiêu tốn các tài nguyên hệ thống quý giá. GPUDirect Storage loại bỏ sự kém hiệu quả này bằng cách cho phép GPU truy cập dữ liệu trực tiếp từ thiết bị lưu trữ thông qua bus PCIe. Đường dẫn trực tiếp này giúp giảm bớt chi phí tài nguyên cho việc di chuyển dữ liệu (overhead), cho phép truyền tải dữ liệu nhanh hơn và hiệu quả hơn.
Các khối lượng công việc AI, đặc biệt là những tác vụ liên quan đến học sâu (deep learning), cực kỳ thâm dụng dữ liệu. Việc đào tạo các mạng thần kinh lớn đòi hỏi phải xử lý hàng terabyte dữ liệu, và bất kỳ sự chậm trễ nào trong quá trình truyền dữ liệu đều có thể dẫn đến việc các GPU không được tận dụng hết công suất và kéo dài thời gian đào tạo. GPUDirect Storage giải quyết thách thức này bằng cách đảm bảo dữ liệu được chuyển đến GPU nhanh nhất có thể, giảm thiểu thời gian nhàn rỗi và tối đa hóa hiệu quả tính toán.
Ngoài ra, GDS đặc biệt có lợi cho các khối lượng công việc liên quan đến truyền tải (streaming) các tập dữ liệu lớn, chẳng hạn như xử lý video, xử lý ngôn ngữ tự nhiên hoặc suy luận thời gian thực. Bằng cách giảm bớt sự phụ thuộc vào CPU, GDS tăng tốc độ di chuyển dữ liệu và giải phóng tài nguyên CPU cho các tác vụ khác, giúp nâng cao hơn nữa hiệu suất tổng thể của hệ thống.
Bên cạnh băng thông thô, GPUDirect kết hợp với NVMe-oF (TCP/RDMA) còn mang lại khả năng I/O với độ trễ cực thấp. Điều này đảm bảo các GPU không bao giờ rơi vào tình trạng “đói” dữ liệu, làm cho hệ thống trở nên lý tưởng cho các quy trình suy luận AI thời gian thực, phân tích dữ liệu và phát lại video.
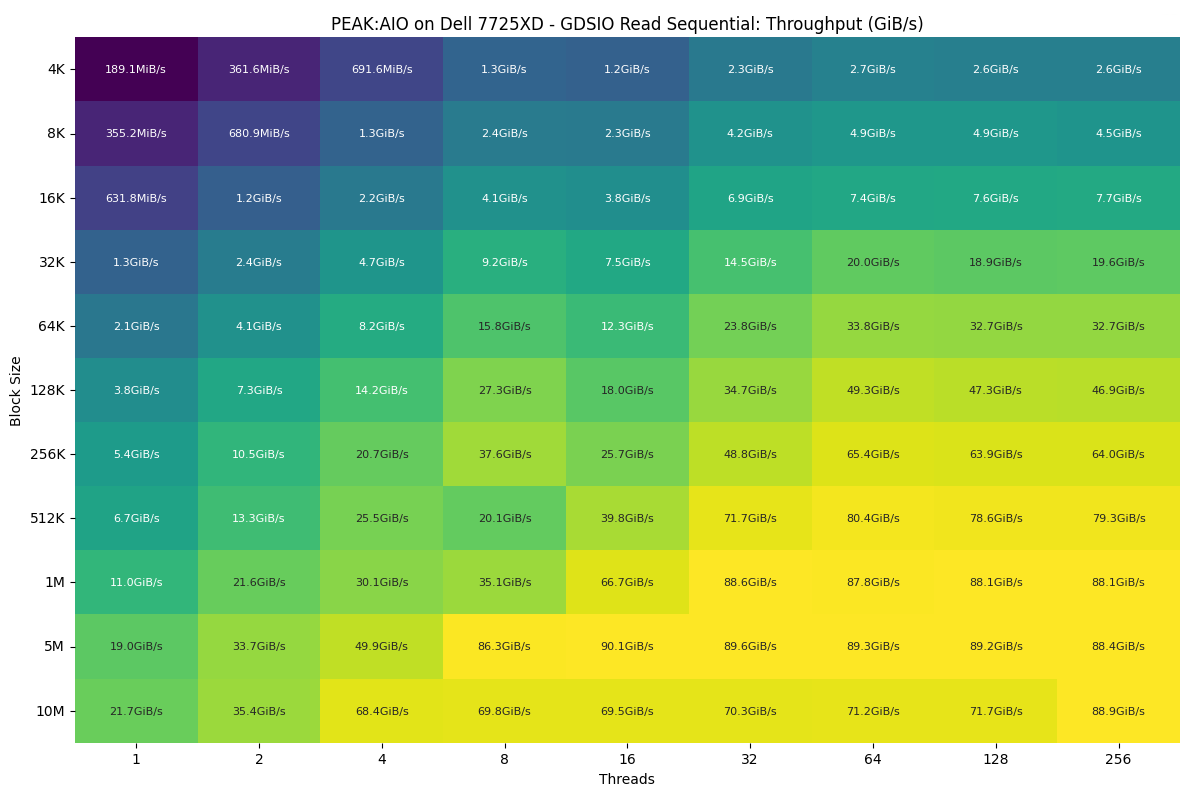
GDSIO – Đọc tuần tự
Khi xem xét PEAK: AIO với một máy khách sử dụng GDSIO, băng thông đọc thể hiện một mô hình mở rộng rõ ràng khi cả kích thước khối và số lượng luồng (thread) đều tăng lên. Máy khách đơn lẻ này được kết nối thông qua hai liên kết 400G, giới hạn tiềm năng tổng thể của nó ở mức 90 GB/s.
Ở các kích thước khối nhỏ nhất và số lượng luồng thấp, hiệu suất ở mức khiêm tốn với tốc độ đọc 4K bắt đầu khoảng 189 MiB/s ở một luồng duy nhất. Ngay khi chúng tôi tăng tính song song của luồng, hệ thống phản hồi lập tức, đạt 691 MiB/s ở bốn luồng và tiến vào phạm vi đa GiB/s khi chúng tôi chuyển sang các khối lớn hơn.
Các kích thước khối tầm trung cho thấy sự nhạy cảm mạnh mẽ nhất đối với số lượng luồng. Tại mức 32K, băng thông tăng từ 1,3 GiB/s ở một luồng lên gần 20 GiB/s với 64 luồng, và chỉ giảm nhẹ sau ngưỡng đó. Một mô hình tương tự cũng xuất hiện ở mức 64K và 128K, nơi hệ thống chuyển đổi từ mức GiB/s đơn vị thấp ở tính song song thấp lên hơn 30 GiB/s khi quy mô khối lượng công việc tăng lên.
Khi đạt đến các kích thước khối lớn hơn, băng thông bắt đầu đi ngang khi hệ thống tiệm cận trần hiệu suất cho một máy khách đơn lẻ. Tại mức 1 MiB, hiệu suất leo từ 11 GiB/s ở một luồng lên khoảng 88 GiB/s ở số lượng luồng cao. Các lần truyền tải 5 MiB và 10 MiB cũng cho thấy mức ổn định tương tự, đạt đỉnh khoảng 89–90 GiB/s bất kể bài kiểm tra đang chạy ở 64, 128 hay 256 luồng.
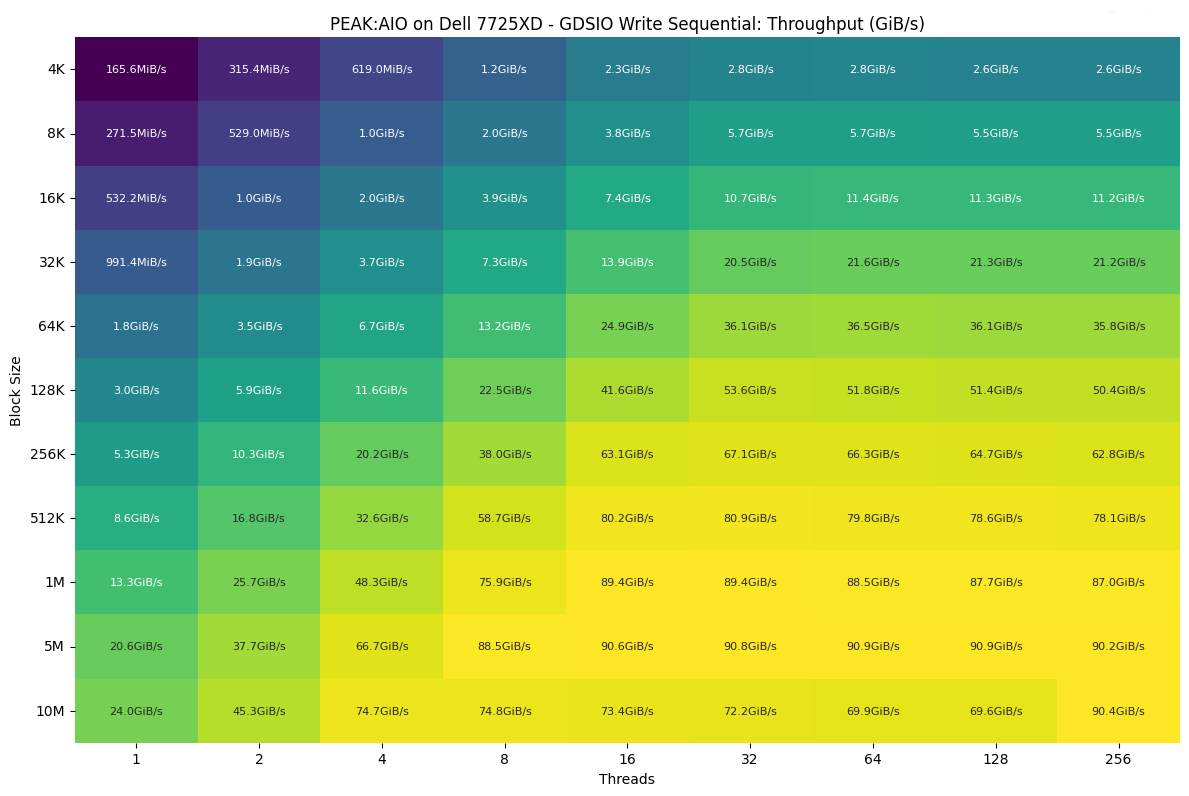
GDSIO – Ghi tuần tự
Ở khía cạnh ghi, hành vi mở rộng tuân theo một mô hình tương tự như khi đọc, nhưng với hiệu suất thấp hơn một chút trên hầu hết các kích thước khối – điều này hoàn toàn nằm trong dự tính đối với các khối lượng công việc ghi tuần tự.
Ở các kích thước khối nhỏ nhất, băng thông bắt đầu ở mức 165 MiB/s cho một luồng duy nhất tại mức 4K và tăng đều đặn khi tính song song tăng lên. Với bốn luồng, con số này tăng lên mức hơn 619 MiB/s trước khi vượt qua ngưỡng 1 GiB/s tại tám luồng.
Các kích thước khối tầm trung cho thấy mức tăng trưởng mạnh mẽ hơn khi số lượng luồng tăng cao. Tại mức 32K, băng thông bắt đầu ở mức dưới 1 GiB/s và mở rộng lên hơn 21 GiB/s ở các mức luồng cao hơn. Các dải 64K và 128K tiếp tục xu hướng này, chuyển dịch từ mức GiB/s đơn vị thấp sang mức giữa 30 GiB/s và 50 GiB/s khi khối lượng công việc trở nên song song hơn.
Hệ thống dần ổn định ở mức trần băng thông ghi tự nhiên khi thực hiện các lần truyền tải lớn hơn. Tại mức 1 MiB, hiệu suất leo từ 13,3 GiB/s ở một luồng lên mức dưới 90 GiB/s ở số lượng luồng cao. Các bài kiểm tra 5 MiB và 10 MiB cũng theo một mô hình tương tự, với kết quả đạt đỉnh quanh mức 90 GiB/s, bất kể hệ thống đang chạy ở 64, 128 hay 256 luồng.
Định nghĩa lại hiệu năng trong kỷ nguyên Gen5
Dell PowerEdge R7725xd không chỉ đơn thuần là một máy chủ lưu trữ; nó đại diện cho một bước chuyển mình trong cách thức phân phối băng thông bên trong tủ rack. Bằng cách loại bỏ các bộ chuyển mạch PCIe và cung cấp cho mỗi ổ đĩa NVMe một đường dẫn trực tiếp tới CPU, Dell đã tạo ra một hệ thống nơi băng thông được mở rộng một cách mạch lạc, các đặc tính nhiệt học luôn ổn định và khả năng xử lý đồng thời trở thành một lợi thế thay vì là một thách thức.
Khi được kết hợp với ổ SSD Micron 9550 PRO và phần mềm I/O song song của PEAK:AIO, R7725xd biến đổi từ một khung máy NVMe mật độ cao thành một “động cơ dữ liệu” thực thụ. Nó có khả năng làm bão hòa cấu trúc PCIe cục bộ, cung cấp dữ liệu cho GPU qua RDMA với tốc độ tối đa của đường truyền, hoặc đóng vai trò vừa là thiết bị tính toán vừa là thiết bị lưu trữ cùng một lúc, tất cả chỉ gói gọn trong một kích thước 2U.

Trên thực tế, cấu hình này mang lại băng thông cục bộ hơn 300 GB/s và hơn 160 GB/s qua mạng, đối đầu trực tiếp với hiệu năng của các cụm lưu trữ đa nút (multi-node) trong khi chỉ tiêu tốn một phần nhỏ chi phí và độ phức tạp. Đây là một minh chứng cho thấy kết quả đạt được khi mọi lớp của ngăn xếp công nghệ, từ silicon đến phần mềm, đều được căn chỉnh xoay quanh hiệu quả và băng thông duy trì.
R7725xd thiết lập một tiêu chuẩn mới cho hiệu suất lưu trữ đơn nút trong kỷ nguyên Gen5. Đối với các tổ chức đang xây dựng các quy trình AI thế hệ mới, phân tích tốc độ cao hoặc các môi trường đào tạo đòi hỏi việc lưu điểm kiểm tra (checkpoint) liên tục, đây là một cái nhìn thực tế về những gì có thể đạt được khi các điểm nghẽn được loại bỏ hoàn toàn ngay từ khâu thiết kế hệ thống.
__________________________________________________
📞 Liên hệ Megacore để được tư vấn cấu hình phù hợp và giải pháp hạ tầng cho doanh nghiệp – hoàn toàn miễn phí
🌐 Website: megacore.net
📧 Email: [email protected]
📲 Hotline: 0345 888 868
Cảm ơn bạn đã tin tưởng và lựa chọn sản phẩm của Megacore. Chúng tôi cam kết mang đến cho bạn những sản phẩm chất lượng và dịch vụ tốt nhất!



