Dell PowerEdge XE7740: Khám phá kiến trúc giải pháp AI cho doanh nghiệp
Thị trường hạ tầng AI không chỉ vận động theo một hướng duy nhất mà đang tách biệt thành hai thế giới riêng biệt. Một bên là các cụm máy chủ huấn luyện tiên phong (frontier training clusters), được xây dựng để phát triển các mô hình nền tảng ở quy mô khổng lồ, gắn chặt với các cấu trúc mạng nội bộ độc quyền và một nhóm hạn chế các bộ tăng tốc. Bên còn lại là thực tế đang mở rộng nhanh chóng của việc suy luận AI (inference) trong doanh nghiệp, nơi các tổ chức triển khai mô hình để phục vụ người dùng, xử lý dữ liệu thực và tạo ra giá trị kinh doanh đo lường được. Dell PowerEdge XE7740 được thiết kế rõ ràng để dành cho thế giới thứ hai này.

Những điểm nhấn chính
PowerEdge XE7740 được xây dựng chuyên biệt cho tác vụ suy luận (inference) doanh nghiệp: Với thiết kế tản nhiệt hai vùng, cấu trúc sơ đồ PCIe Gen5 tối ưu và khả năng kết nối mạng mở rộng (scale-out), máy chủ này hoàn toàn tương thích với các khối lượng công việc thực tế trongmôi trường sản xuất.
Sự cân bằng hệ thống có tính toán: Kết hợp mật độ nhân xử lý cao của dòng chip Xeon 6, băng thông bộ nhớ lớn và chuẩn lưu trữ PCIe Gen5 E3.S NVMe để hỗ trợ hiệu quả việc giải phóng bộ nhớ đệm KV (KV cache offload) và điều phối hệ thống.
Tính linh hoạt về phần cứng là nền tảng: Hỗ trợ đa dạng các bộ tăng tốc chuẩn PCIe Gen5, giúp doanh nghiệp có nhiều lựa chọn về chip xử lý mà không buộc phải thiết kế lại toàn bộ hạ tầng.
Khả năng mở rộng liền mạch theo thời gian: Hệ thống có thể nâng cấp linh hoạt, từ việc lắp đặt một phần số lượng GPU trong một khung máy đơn lẻ cho đến việc triển khai suy luận phân tán trên toàn bộ tủ rack nhờ vào 8 khe cắm mạng chuyên dụng PCIe Gen5 x16 ở phía sau.
Cốt lõi của XE7740 là cam kết về sự đa dạng của các dòng chip xử lý (silicon diversity). Thay vì đóng khung nền tảng vào một lộ trình bộ tăng tốc duy nhất, Dell đã xây dựng một hệ thống có khả năng thích ứng với nguồn cung, chi phí và mức độ sẵn sàng của từng tổ chức. XE7740 hỗ trợ hàng loạt bộ tăng tốc PCIe Gen5, bao gồm các dòng GPU của NVIDIA như RTX PRO 6000, H100/200, L40S, L4 và A16 dành cho các tổ chức coi trọng khả năng tương thích hệ sinh thái rộng rãi; đồng thời hỗ trợ Intel Gaudi 3 cho các đội ngũ tìm kiếm một lộ trình suy luận tiết kiệm chi phí và dễ tiếp cận hơn. Các bộ tăng tốc Gaudi 3 hiện đã sẵn hàng, cho phép các tổ chức chuyển từ giai đoạn lập kế hoạch sang triển khai thực tế mà không gặp phải sự chậm trễ trong khâu thu mua vốn thường ảnh hưởng đến chiến lược trang bị bộ tăng tốc.
Khi suy luận (inference) trở thành khối lượng công việc AI chiếm ưu thế, thì tính sẵn có và cấu trúc chi phí trở nên cực kỳ quan trọng. Hầu hết các doanh nghiệp không huấn luyện các mô hình quy mô tiên phong; họ đang vận hành các luồng suy luận, phục vụ các mô hình ngôn ngữ quy mô trung bình, thực hiện quy trình tạo phản hồi tăng cường tra cứu (RAG) và triển khai thị giác máy tính vào sản xuất. Trong bối cảnh đó, Gaudi 3 được định vị là một trong những bộ tăng tốc suy luận hiện đại có giá thành hợp lý nhất trên thị trường, cung cấp kiến trúc tân tiến với bộ nhớ băng thông cao và khả năng mở rộng dựa trên Ethernet mà không tốn kém như các dòng GPU hàng đầu chuyên dùng cho huấn luyện. Trong hệ thống XE7740, Gaudi 3 không nhằm mục đích thay thế hoàn toàn mà tập trung vào việc hiện thực hóa các hoạt động triển khai suy luận bền vững.
Nền tảng bao quanh các bộ tăng tốc cũng được thiết kế kỹ lưỡng không kém. XE7740 được xây dựng trên bộ vi xử lý Intel Xeon 6, và trong các hệ thống tập trung vào suy luận, CPU vẫn là một thành phần then chốt. Số lượng nhân lớn và băng thông bộ nhớ tăng cao cung cấp mức tài nguyên dự phòng cần thiết cho các tác vụ lập lịch, phân tách từ (tokenization), tiền xử lý và điều phối—vốn nằm trực tiếp trên lộ trình xử lý quan trọng của suy luận. Ổ lưu trữ E3.S NVMe gắn phía trước hỗ trợ đắc lực cho việc chuẩn bị dữ liệu cục bộ và giải phóng bộ nhớ đệm KV (KV cache offload), giúp giảm tải cho bộ tăng tốc và cải thiện hiệu suất tổng thể của hệ thống. Thiết kế cân bằng này phản ánh một sự hiểu biết sâu sắc rằng: hiệu năng suy luận được định hình bởi toàn bộ hệ thống chứ không chỉ riêng bộ tăng tốc.

XE7740 cũng được thiết kế để có khả năng mở rộng linh hoạt theo thời gian. Các tổ chức có thể bắt đầu với cấu hình vừa phải — ví dụ như hai hoặc bốn bộ tăng tốc (accelerators) — để khai thác giá trị ngay lập tức mà không cần lắp đầy toàn bộ khung máy (chassis). Khi nhu cầu tăng lên, chính nền tảng này có thể mở rộng theo chiều dọc hoặc chuyển đổi sang mô hình suy luận phân tán (distributed inference).
Tám khe cắm PCIe Gen5 x16 ở mặt sau cung cấp băng thông chuyên dụng cho kết nối mạng tốc độ cao, cho phép XE7740 đóng vai trò như một khối cấu trúc (building block) để thiết lập các cụm suy luận mở rộng (scale-out clusters). Ngoài ra, tùy chọn hỗ trợ DPU giúp gia tăng tính linh hoạt bằng cách đảm nhận các tác vụ mạng và truyền thông khi hệ thống vận hành đi vào giai đoạn ổn định.
Thông số kĩ thuật: Dell PowerEdge XE7740
| Specification | PowerEdge XE7740 |
|---|---|
| Features of PowerEdge XE7740 | |
| Processor | Two Intel® Xeon® 6 series processors, with up to 86 cores per processor |
| Slots | |
| PCIe Accelerators | 8x PCIe Gen 5 x16 DW-FHFL up to 600 W, or
16x PCIe Gen 5 x16 SW-FHFL up to 75 W |
| PCIe NICs |
|
| Form factor | |
| Form factor | 4U rack server |
| Memory | |
| DIMM speed, maximum capacity | Up to 6400 MT/s, 4 TB max |
| Memory module slots | 32 DDR5 DIMM slots Supports registered ECC DDR5 RDIMM only. |
| Storage | |
| Front bays | Up to 8 x EDSFF E3.S Gen5 NVMe (SSD) max 122.88 TB |
| Storage controllers | |
| Internal boot | Boot Optimized Storage Subsystem (BOSS-N1 DC-MHS): HWRAID 1, 2 x M.2
NVMe SSDs |
| Power supply | |
| Power supply | 3200 W Titanium 200-240 V AC or 240 V DC, hot swap redundant
Multi-capacity for 3200 W PSU:
Multi-capacity for 2400 W PSU:
CAUTION: The system requires at least one PSU in the CPU zone and one PSU in the GPU zone to maintain BMC and standby power. If the GPU zone has no PSU installed, then the system will remain on hold. To ensure full redundancy, install N+N PSUs in each zone: 1+1 in the CPU zone and 3+3 in the GPU zone. Removing all PSUs from the CPU zone while the system is powered on will cause an immediate shutdown and may result in data loss. |
| Cooling Options | |
| Cooling Options | Air Cooling |
| Fans | Up to four sets of high-performance (HPR) platinum-grade fans (dual fan module) installed in the mid tray
Up to twelve high-performance (HPR) platinum-grade fans installed on the front of the system All are hot-swap fans |
| Ports | |
| Network options | 1 PCIe Gen 5 OCP 3.0 Compatible I/O (supported by x8 PCIe lanes) |
| Front ports | 1 x USB 2.0 Type-A (optional) 1 x Mini-Display port (optional) 1 x USB 2.0 Type-C dual mode (Host/iDRAC Direct port) |
| Rear ports | 1 x Dedicated iDRAC/BMC Direct Ethernet port 2 x USB 3.1 Type A port 1 x VGA |
| Internal ports | 1 x USB 3.1 Type-A |
Thiết kế và Cấu trúc của XE7740
Kiến trúc Hai vùng (Dual-Zone): Tách biệt CPU và GPU
Một trong những lựa chọn thiết kế đặc trưng nhất của XE7740 là việc phân tách vật lý thành hai vùng nhiệt và năng lượng riêng biệt.
- Vùng CPU: Chiếm phần không gian 1U phía trên, bao gồm cả hai bộ xử lý Xeon 6, toàn bộ 32 khe cắm DIMM, hệ thống lưu trữ và mô-đun quản lý DC-SCM. Vùng CPU này sử dụng bốn bộ mô-đun quạt kép hiệu suất cao (kích thước 40×40×56mm), cung cấp lưu lượng không khí lên đến 47.4 CFM.

Phần 3U bên dưới là vùng GPU, nơi chứa toàn bộ các khe cắm bộ tăng tốc với cơ sở hạ tầng làm mát chuyên dụng riêng, cùng với Bo mạch nền PCIe (PBB), các khe cắm mở rộng PCIe hướng ra phía sau và kết nối OCP NIC.
Vùng GPU sử dụng mười hai quạt hiệu suất cao loại lớn (kích thước 60×60×56mm) với công suất lưu lượng gió lên đến 122.2 CFM mỗi quạt—cao hơn đáng kể so với quạt ở vùng CPU. Tất cả các quạt đều có khả năng thay thế nóng (hot-swappable).
Cách làm mát hai vùng này giúp đảm bảo rằng nhu cầu tản nhiệt cực lớn từ các bộ tăng tốc có chỉ số TDP cao (lên đến 600W mỗi card) sẽ không gây ảnh hưởng đến hiệu quả làm mát của CPU và bộ nhớ, và ngược lại, ngay cả khi lắp đặt trong tủ rack 19-inch tiêu chuẩn.

Dell đã dành sự quan tâm đặc biệt đến việc tối ưu hóa luồng không khí bên trong XE7740. Các hệ thống có mật độ bộ tăng tốc cao vốn dĩ đòi hỏi lượng lớn dây cáp nội bộ, bao gồm dây cấp nguồn phụ cho GPU, cáp tín hiệu PCIe giữa bo mạch HPM và bo mạch nền PBB, cùng các kết nối bảng mạch quạt.
Trong XE7740, các loại cáp này được đi dọc theo vách ngăn của khung máy bằng các giá đỡ cố định và hệ thống nắp đậy cáp chuyên dụng. Mỗi sợi cáp đều được chế tạo với độ dài chính xác theo yêu cầu; hoàn toàn không có tình trạng dư thừa các bó dây bên trong hệ thống. Bằng cách loại bỏ dây cáp khỏi kênh dẫn khí trung tâm, thiết kế này duy trì được một đường lưu thông không khí thông suốt từ trước ra sau và giảm thiểu tối đa lực cản (trở lực) trên cả hai vùng làm mát CPU và GPU.

Trong một bộ khung máy chủ (chassis) chứa tới tám bộ tăng tốc (GPU/Accelerator) với công suất 600W mỗi chiếc, ngay cả những vật cản nhỏ nhất trên đường đi của luồng khí cũng có thể tạo ra các điểm nóng cục bộ. Điều này buộc hệ thống quạt phải đẩy tốc độ vòng quay lên cao hơn — dẫn đến việc tăng cả mức tiêu thụ điện năng lẫn tiếng ồn phát ra.
Phương pháp quản lý cáp của Dell được thiết kế để giữ cho khu vực trung tâm của thân máy luôn thông thoáng, giúp luồng khí lưu thông trực tiếp và không bị cản trở tới các linh kiện tỏa nhiệt nhiều nhất, đảm bảo hiệu quả làm mát tối ưu.
Cấu trúc liên kết PCIe và luồng dữ liệu
Hệ thống con PCIe của XE7740 được xây dựng xung quanh bốn bộ chuyển mạch (switch) PCIe Gen 5 trên bo mạch nền PCIe (PBB), được ký hiệu từ SW1 đến SW4. Các bộ chuyển mạch này đóng vai trò là xương sống cho kiến trúc I/O của hệ thống, kết nối các bộ tăng tốc (GPU), mạng và lưu trữ với hai bộ xử lý Xeon 6 theo một cấu trúc liên kết được tổ chức chặt chẽ.
16 khe cắm GPU nội bộ được chia thành hai nhóm (mỗi nhóm 8 khe), mỗi nhóm được phục vụ bởi một cặp bộ chuyển mạch PCIe, và mỗi bộ chuyển mạch lại kết nối ngược dòng (upstream) tới một CPU. Trong mỗi nhóm, các cặp khe cắm GPU độ rộng kép (double-width) nằm kề nhau được bố trí xen kẽ giữa hai bộ chuyển mạch:
- Về phía CPU0: SW1 phục vụ các khe GPU 21 và 25, cùng các khe PCIe phía sau 8 và 9; trong khi SW2 phục vụ các khe GPU 23 và 27, cùng các khe PCIe phía sau 6 và 7.
- Về phía CPU1: SW3 phục vụ các khe GPU 29 và 33, cùng các khe PCIe phía sau 3 và 4; trong khi SW4 phục vụ các khe GPU 31 và 35, cùng các khe PCIe phía sau 1 và 2.
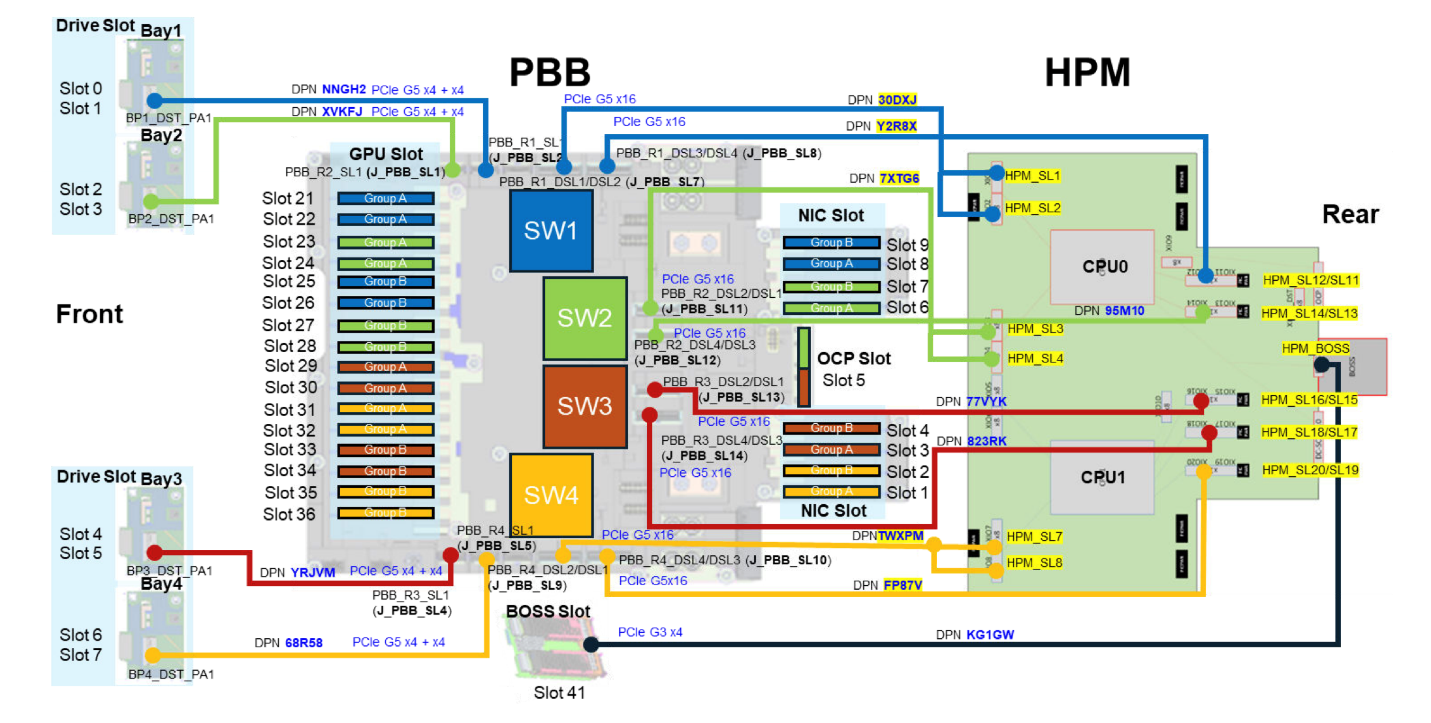
Do đó, mỗi phân vùng CPU (CPU domain) sở hữu: bốn khe cắm bộ tăng tốc (accelerator) độ rộng kép, bốn khe cắm NIC/I/O phía sau, và bốn trong số tám khoang lưu trữ NVMe E3.S ở mặt trước.
Cấu trúc chuyển mạch (switch topology) này có ý nghĩa quan trọng đối với luồng dữ liệu, đặc biệt là lưu lượng dựa trên giao thức RDMA. Vì mỗi bộ chuyển mạch (switch) quản lý cả các khe cắm bộ tăng tốc và các khe cắm card mạng (NIC) phía sau, nên một bộ tăng tốc và một bộ thích nghi mạng (network adapter) nằm trên cùng một switch có thể thực hiện truyền dữ liệu RDMA hoàn toàn bên trong cấu trúc của switch đó.
Dữ liệu không bao giờ cần phải đi qua tổ hợp gốc (root complex) của CPU, từ đó loại bỏ được ‘vùng đệm trung gian’ (CPU bounce buffer) – thứ vốn dĩ bắt buộc phải có khi một thiết bị PCIe ở cổng gốc này muốn giao tiếp với một thiết bị ở cổng gốc khác. Điều này giúp giảm độ trễ, tránh tiêu tốn băng thông bộ nhớ quý giá của CPU và giải phóng các chu kỳ xử lý của CPU cho những tác vụ khác.

Việc giao tiếp bên trong một phân vùng CPU duy nhất — giữa hai bộ chuyển mạch (switch) của nó — sẽ định tuyến thông qua ‘tổ hợp gốc’ (root complex) của CPU nhưng vẫn nằm trong phạm vi cục bộ của socket đó.
Tuy nhiên, việc giao tiếp liên CPU (cross-CPU) bắt buộc phải đi qua các đường liên kết UPI giữa hai bộ xử lý Xeon 6. Dòng chip 6787P cung cấp bốn đường liên kết UPI 2.0 với tốc độ 24 GT/s mỗi đường, mang lại băng thông liên socket rất lớn. Mặc dù vậy, lưu lượng dữ liệu giữa một bộ tăng tốc (GPU) trên cụm switch của CPU0 và một card mạng (NIC) trên cụm switch của CPU1 chắc chắn sẽ có độ trễ cao hơn so với việc truyền tải nội bộ trong một switch hoặc trong cùng một socket.
Bản thân các bộ chuyển mạch không được kết nối trực tiếp với nhau. Mọi lưu lượng dữ liệu giữa các switch đều phải định tuyến qua root complex của CPU, vì vậy việc hiểu rõ mối quan hệ tương thích (affinity) giữa các khe cắm GPU, khe cắm NIC, ổ cứng lưu trữ và các socket CPU là cực kỳ quan trọng. Để đơn giản hóa sự phức tạp này cho các doanh nghiệp, Dell cung cấp các cấu hình đã được xác thực và tối ưu hóa cho các dòng bộ tăng tốc phổ biến
Hệ thống cấp nguồn hai phân vùng (Dual-Zone)
Hệ thống cấp nguồn của XE7740 mô phỏng theo cấu trúc tản nhiệt của nó với thiết kế bộ nguồn (PSU) hai phân vùng khá lạ lẫm. Hệ thống hỗ trợ tối đa tám bộ nguồn có thể thay thế nóng (hot-swappable), được chia thành hai vùng: Vùng 1 (Vùng CPU) bao gồm các bộ nguồn PSU 1 và 2, trong khi Vùng 2 (Vùng GPU) chứa các bộ nguồn từ PSU 3 đến PSU 8.

Hệ thống yêu cầu ít nhất một bộ nguồn (PSU) ở mỗi phân vùng để duy trì hoạt động của bộ điều khiển BMC và nguồn dự phòng (standby power). Nếu bất kỳ phân vùng nào bị mất nguồn điện xoay chiều (AC) trong khi hệ thống đang chạy, máy chủ sẽ lập tức tắt nguồn để ngăn ngừa mất mát dữ liệu.
Các phân vùng này phụ thuộc lẫn nhau để vận hành, mặc dù chúng được tách biệt về mặt vật lý và điện năng. Để đạt được sự dự phòng toàn diện, Dell khuyến nghị cấu hình 1+1 ở phân vùng CPU và cấu hình 3+3 ở phân vùng GPU. Điều này có nghĩa là cả tám khoang PSU nên được lắp đầy để đảm bảo hệ thống có khả năng dự phòng lỗi hoàn chỉnh

Dell AIOps, Quản trị và Độ tin cậy cho Doanh nghiệp
Nền tảng PowerEdge của Dell đã tạo dựng được uy tín trong ngành về độ tin cậy và khả năng bảo trì. Các khách hàng doanh nghiệp thường xuyên nhấn mạnh vào những giá trị tương tự: hệ thống PowerEdge được chế tạo để hoạt động bền bỉ, tổ chức hỗ trợ của Dell giải quyết các sự cố nhanh chóng, và các công cụ quản trị của họ đã đạt đến độ chín muồi cũng như được tích hợp rất tốt.
Dòng XE7740 tiếp tục kế thừa truyền thống này, đồng thời Dell đã thực hiện những tiến bộ rõ rệt trong cả việc quản lý phần cứng và bảo mật với thế hệ máy chủ mới này.
iDRAC 10
XE7740 được xuất xưởng với thế hệ tiếp theo iDRAC 10 của Dell, một sự thay đổi diện mạo đáng kể so với iDRAC 9 vốn đã rất mạnh mẽ mà khách hàng của Dell tin dùng trong nhiều năm qua. Được triển khai dưới dạng Mô-đun Điều khiển Bảo mật Trung tâm Dữ liệu (DC-SCM) tuân theo tiêu chuẩn OCP DC-MHS, iDRAC 10 không đơn thuần là một bản cập nhật firmware; nó đại diện cho một nền tảng phần cứng mới. Bộ điều khiển này sở hữu bốn nhân 1 GHz với kiến trúc 64-bit và 2 GB bộ nhớ DDR4 (gấp đôi so với thế hệ trước), mang lại hiệu suất và khả năng phản hồi được cải thiện rõ rệt cho các thao tác quản trị.
Về mặt bảo mật, iDRAC 10 giới thiệu nhiều cải tiến đáng chú ý. Nền tảng này hỗ trợ các chuẩn mã hóa mạnh mẽ hơn trên toàn hệ thống, bao gồm xác thực SHA-384, SHA-512 và mã hóa AES-256 an toàn lượng tử (quantum-safe), nhằm chuẩn bị cho các mối đe dọa mật mã trong kỷ nguyên hậu lượng tử.
Một “vùng bảo mật tích hợp” biệt lập (dedicated integrated security enclave) bên trong chip iDRAC 10 sẽ quản lý các chức năng phục hồi an ninh mạng, bao gồm xác thực cấp thiết bị và công nghệ Root-of-Trust tùy chỉnh của Dell. Công nghệ Root-of-Trust dựa trên phần cứng này đảm bảo rằng tất cả firmware (BIOS, iDRAC và firmware của các linh kiện) đều được xác thực bằng mã hóa trước khi thực thi, giúp chống lại các cuộc tấn công chuỗi cung ứng và giả mạo firmware.
Tính năng Xác minh linh kiện bảo mật (Secured Component Verification) giúp xác nhận rằng các hệ thống xuất xưởng từ nhà máy của Dell đến tay khách hàng với đúng chính xác các linh kiện và cấu hình đã đặt, duy trì tính toàn vẹn từ khâu sản xuất đến khi triển khai. Ngoài ra, firmware iDRAC 10 mới nhất cũng mang đến một giao diện người dùng dạng mô-đun được làm mới, giúp cải thiện trải nghiệm quản trị hàng ngày.
OpenManage Enterprise
Để quản lý số lượng lớn máy chủ (fleet management), phần mềm OpenManage Enterprise (OME) của Dell cung cấp khả năng giám sát tập trung, cập nhật firmware và quản lý cấu hình trên toàn bộ các hệ thống PowerEdge được triển khai.
Một sự bổ sung đáng chú ý gần đây dành cho các hệ thống chuyên dụng cho AI là OME hiện đã hỗ trợ hiển thị trực tiếp các thông số thống kê của GPU và bộ tăng tốc: bao gồm mức tiêu thụ điện năng, nhiệt độ, hiệu suất sử dụng (utilization), số lỗi phát sinh, và nhiều thông số khác mà không cần đến các công cụ riêng biệt từ nhà sản xuất card (như NVIDIA hay AMD).
Đối với các tổ chức đang vận hành hàng chục hoặc hàng trăm nút mạng XE7740 trong một cụm suy luận (inference cluster), mặt phẳng quản trị thống nhất (unified management plane) này là một bước đơn giản hóa đáng kể về mặt vận hành.
Intel Xeon 6
Trung tâm của máy chủ XE7740 là hai bộ xử lý Intel Xeon 6 6787P, dòng chip đầu bảng của hệ sê-ri Xeon 6700P. Được xây dựng trên kiến trúc Granite Rapids sử dụng tiến trình Intel 3nm, chip 6787P cung cấp tới 86 nhân hiệu năng cao (P-cores) với 172 luồng trên mỗi socket, mức tiêu thụ điện năng (TDP) là 350W, xung nhịp cơ bản 2.0 GHz và xung nhịp tăng tốc (turbo) đạt 3.8 GHz.
Điều khiến kiến trúc Granite Rapids trở nên đặc biệt phù hợp cho hạ tầng AI chính là sự kết hợp giữa số lượng nhân cực lớn và hệ thống phụ trợ bộ nhớ (memory subsystem) của nó. Mỗi bộ xử lý 6787P cung cấp 8 kênh bộ nhớ DDR5 với tốc độ lên đến 6400 MT/s. Với một chiếc XE7740 chạy hai socket được lắp đầy 32 thanh RAM (DIMM), hệ thống có thể được cấu hình để đạt tổng dung lượng bộ nhớ hệ thống lên tới 4 TB.

Dung lượng và băng thông bộ nhớ là những yếu tố then chốt đối với các khối lượng công việc AI, đặc biệt là khi áp dụng kỹ thuật đẩy bộ nhớ đệm KV (KV cache offloading) sang bộ phận khác. Khi các mô hình ngôn ngữ lớn tăng chiều dài ngữ cảnh (context length), bộ nhớ đệm KV cũng tăng theo tỷ lệ thuận và có thể tiêu tốn một lượng đáng kể bộ nhớ của bộ tăng tốc (HBM trên GPU).
Việc đẩy một phần bộ nhớ đệm KV sang bộ nhớ hệ thống (RAM) hoặc ổ cứng lưu trữ tốc độ cao giúp bộ nhớ HBM của GPU được sử dụng hiệu quả hơn cho các tính toán đang thực thi, từ đó giảm thời gian phản hồi token đầu tiên (TTFT) trong các cuộc hội thoại nhiều lượt.
Cũng cần lưu ý đến các đơn vị xử lý tensor AMX của Xeon 6, vốn đảm nhiệm một lượng công việc đáng kể ở phía CPU. Các tác vụ này bao gồm tiền xử lý, mã hóa từ ngữ (tokenization) và các tác vụ suy luận hỗn hợp liên quan đến các phép toán ma trận. Điều này trở nên đặc biệt hữu ích với các khung làm việc (framework) suy luận như SGLang, vốn sử dụng CPU để quản lý bộ nhớ đệm KV theo cấu trúc cây Radix (Radix Tree) và lập lịch không độ trễ (Zero Overhead scheduling).
Card mở rộng Intel Gaudi 3: Khả năng suy luận cạnh tranh ở quy mô lớn
Gaudi 3 là bộ tăng tốc AI chủ lực của Intel, được ra mắt vào quý 4 năm 2024. Intel đang định vị dòng bộ tăng tốc này một cách rất quyết liệt; thay vì cạnh tranh trực diện với các bộ tăng tốc huấn luyện trung tâm dữ liệu phân khúc cao cấp nhất, Gaudi 3 được nhắm thẳng vào phân khúc suy luận (inference).

Việc suy luận các mô hình dựa trên kiến trúc Transformer trong tất cả các LLM phổ biến hiện nay về cơ bản đều bị giới hạn bởi bộ nhớ (memory-bound). Trong giai đoạn giải mã (decode phase) của quá trình tạo văn bản tự hồi quy (autoregressive generation), mô hình sẽ tạo ra từng token một, đồng thời phải đọc các trọng số của mô hình và các thực thể trong bộ nhớ đệm KV cho mỗi token được tạo ra. Điểm nghẽn ở đây không nằm ở khả năng tính toán mà nằm ở băng thông bộ nhớ — tức là tốc độ mà bộ tăng tốc có thể truyền dữ liệu từ bộ nhớ HBM vào các nhân tính toán.
Gaudi 3 sở hữu 128 GB bộ nhớ HBM2e với băng thông bộ nhớ lên tới 3.7 TB/s. Về mặt kiến trúc, Gaudi 3 được xây dựng trên tiến trình 5nm của TSMC và sử dụng thiết kế chiplet hai đế (dual-die): hai đế silicon giống hệt nhau được ghép nối bởi một kết nối băng thông cao, xuất hiện dưới dạng một thiết bị thống nhất duy nhất đối với phần mềm.
Khối tính toán được tổ chức thành bốn Lõi Học Sâu (DCOREs), mỗi lõi chứa 2 công cụ nhân ma trận (MMEs), 16 bộ xử lý tensor (TPCs) và 24 MB bộ nhớ đệm SRAM cục bộ. Tổng cộng 96 MB SRAM trên chip cung cấp băng thông nội bộ lên tới 12.8 TB/s. Bộ tăng tốc này cũng tích hợp 14 bộ giải mã đa phương tiện chuyên dụng (H.265, H.264, JPEG, VP9), cho phép tiền xử lý hình ảnh nhanh chóng cho các khối lượng công việc đa phương thức (multi-modal).

Phần lớn các mô hình AI mã nguồn mở tiên tiến (frontier models) được phát hành hiện nay đều được huấn luyện nguyên bản trên định dạng FP8, hoặc là các mô hình lai (hybrid) kết hợp giữa trọng số FP8 (E4M3) và BF16.
Gaudi 3 cung cấp khả năng tăng tốc FP8 nguyên bản cho các định dạng này thông qua 8 Công cụ Nhân Ma trận (MMEs) và 64 Lõi Xử lý Tensor (TPCs), mang lại hiệu suất tính toán FP8 lên tới 1.8 PFlops.

Gaudi 3 cũng tích hợp sẵn công nghệ mạng RDMA qua Ethernet hội tụ (RoCEv2) trực tiếp vào trong silicon, với 24 cổng 200 GbE trên phiên bản OAM (dạng mô-đun).
Mặc dù biến thể card rời PCIe được sử dụng trong máy chủ XE7740 không đưa toàn bộ các cổng này ra ngoài theo cùng một cách, nhưng các phiên bản card rời này vẫn hỗ trợ kết nối cầu (bridging) giữa 4 card với nhau để tăng tốc độ giao tiếp nội bộ giữa chúng.
Hiệu năng và kkiểm thử (Benchmarks)
Cấu hình hệ thống XE7740 thử nghiệm:
- 2 x Bộ xử lý Intel Xeon 6787P (86 nhân, 2.00 GHz)
- 2TB RAM DDR5 (32 x 64GB tốc độ 5200MT/s)
- 4 x Bộ tăng tốc AI Intel Gaudi 3 PCIe với 128GB HBM
- Hệ điều hành: Ubuntu 24.04.5 Server
Hiệu năng phục vụ trực tuyến vLLM Để đánh giá khả năng tính toán của Dell XE7740 chạy chip Gaudi 3, chúng tôi đã kiểm thử hiệu năng phục vụ trực tuyến của vLLM trên nhiều mô hình phổ biến với các kiến trúc, số lượng tham số và định dạng độ chính xác khác nhau. Mỗi mô hình được thử nghiệm qua ba kịch bản tải công việc với số lượng yêu cầu đồng thời tăng dần từ 1 đến 128.
Suy luận LLM bao gồm hai giai đoạn riêng biệt:
- Giai đoạn Prefill (Nạp trước): Xử lý tất cả các token đầu vào song song trước khi tạo ra bất kỳ token đầu ra nào. Đây là thao tác bị giới hạn bởi khả năng tính toán (compute-bound) và tăng tuyến tính theo số lượng token đầu vào.
- Giai đoạn Decode (Giải mã): Tạo ra từng token đầu ra một (tự hồi quy). Mỗi token mới yêu cầu đọc toàn bộ trọng số mô hình từ bộ nhớ nhưng thực hiện rất ít tính toán trên mỗi token — làm cho nó bị giới hạn bởi băng thông bộ nhớ (memory-bandwidth bound).
Hai giai đoạn này gây áp lực lên các phần khác nhau của bộ tăng tốc, vì vậy chúng tôi thử nghiệm ba kịch bản tải để thay đổi sự cân bằng giữa chúng:
- Cân bằng (Equal): (1024 token vào/1024 token ra) đại diện cho các tương tác chat thông thường.
- Nặng về Prefill (Prefill Heavy): (8192 vào/1024 ra) mô phỏng kỹ thuật RAG hoặc tóm tắt văn bản dài, nơi hệ thống phải xử lý ngữ cảnh đầu vào khổng lồ.
- Nặng về Decode (Decode Heavy): (1024 vào/8192 ra) đại diện cho việc tạo nội dung dài, nơi băng thông bộ nhớ duy trì sẽ quyết định thông lượng.
Chúng tôi tập trung vào hai chỉ số chính:
- Tổng thông lượng token (Total token throughput): Đo bằng số token trên giây, thể hiện năng lực phục vụ tổng thể của hệ thống dưới tải trọng.
- Thời gian phản hồi token đầu tiên (TTFT): Đo độ trễ từ khi gửi yêu cầu đến khi nhận được chữ đầu tiên. Vì giai đoạn Prefill phải hoàn tất trước khi phát ra token đầu tiên, TTFT gắn liền trực tiếp với hiệu suất tính toán của bộ tăng tốc.
Lưu ý về kết quả độ chính xác FP8: Mặc dù Gaudi 3 hỗ trợ tăng tốc FP8 nguyên bản (lý thuyết sẽ nhanh hơn BF16), nhưng kết quả FP8 trong bài thử nghiệm này lại thấp hơn BF16. Đây không phải giới hạn phần cứng mà là vấn đề về độ chín muồi của phần mềm trong phiên bản vLLM của Intel mà chúng tôi đã thử nghiệm. Intel hiện có phiên bản vLLM dạng plugin mới (bản beta) hứa hẹn sẽ khắc phục các thách thức về hiệu năng này.
Mô hình Llama 3.1 8B Instruct Đây là mô hình Transformer dạng “dense” từ Meta, nghĩa là mọi tham số đều hoạt động cho mỗi token được tạo ra. Với 8 tỷ tham số, nó là một trong những mô hình mã nguồn mở phổ biến nhất cho các tác vụ hàng ngày như tóm tắt tài liệu ngắn, soạn email, trả lời câu hỏi đơn giản và vận hành chatbot cần tốc độ và hiệu quả chi phí hơn là khả năng suy luận chuyên sâu.
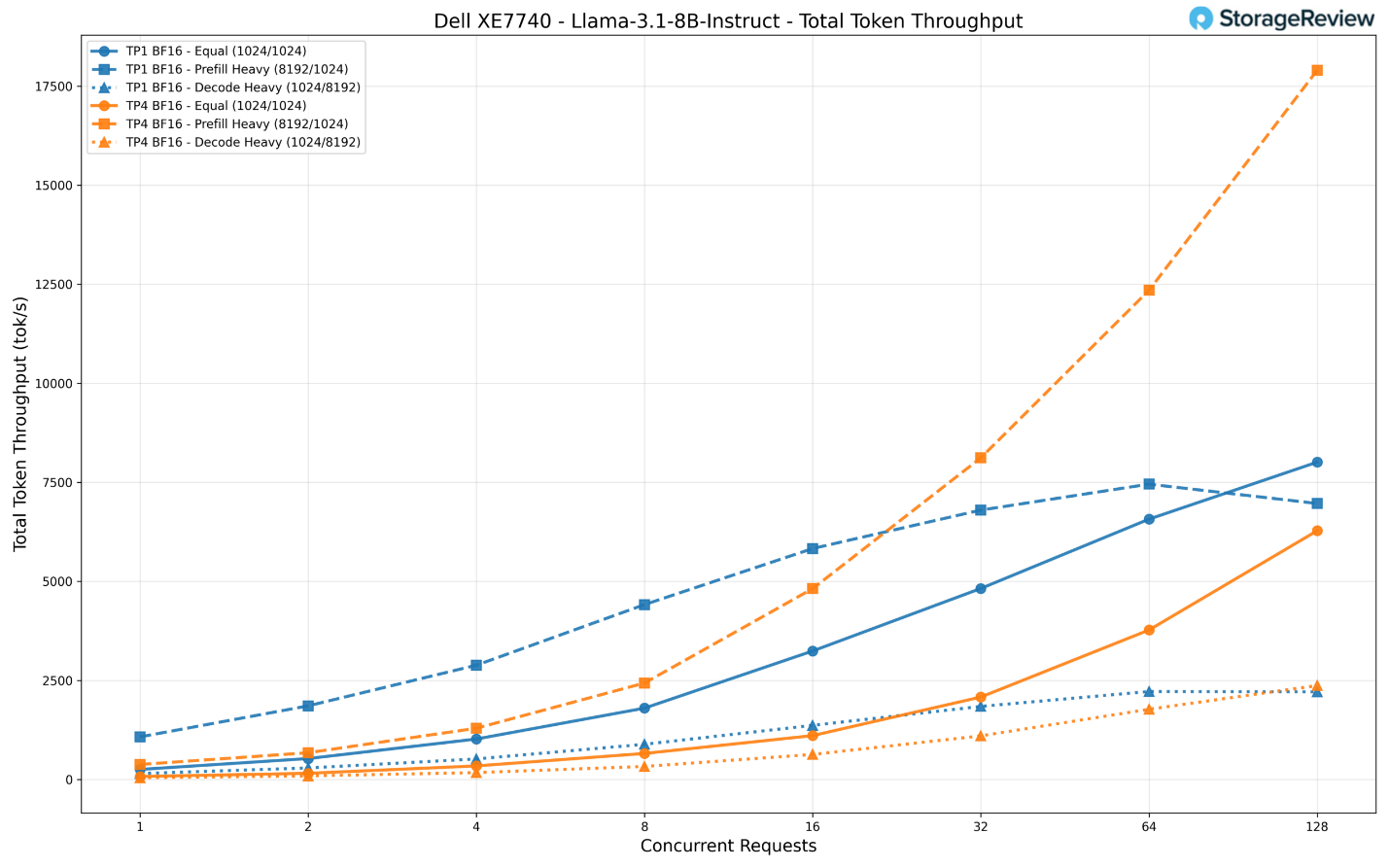
Chúng tôi đã thử nghiệm mô hình này ở cả hai cấu hình: TP1 (sử dụng một bộ tăng tốc duy nhất) và TP4 (sử dụng tất cả bốn bộ tăng tốc Gaudi 3).
Khi chạy ở chế độ TP1, mô hình đạt tổng thông lượng khoảng 8.000 token/giây với 128 yêu cầu đồng thời trong kịch bản tải cân bằng (equal workload), tăng trưởng ổn định từ mức khoảng 250 token/giây khi chỉ có một yêu cầu duy nhất.
Kịch bản nặng về Prefill (nạp dữ liệu đầu vào) cho thấy một mô hình phân bổ thú vị: trong khi TP1 đạt đỉnh ở mức khoảng 7.000 token/giây, thì TP4 đã tăng vọt lên hơn 17.900 token/giây với 128 yêu cầu đồng thời. Điều này cho thấy hệ thống đã tận dụng hiệu quả các bộ tăng tốc bổ sung để xử lý ngữ cảnh đầu vào khổng lồ một cách tối ưu hơn.
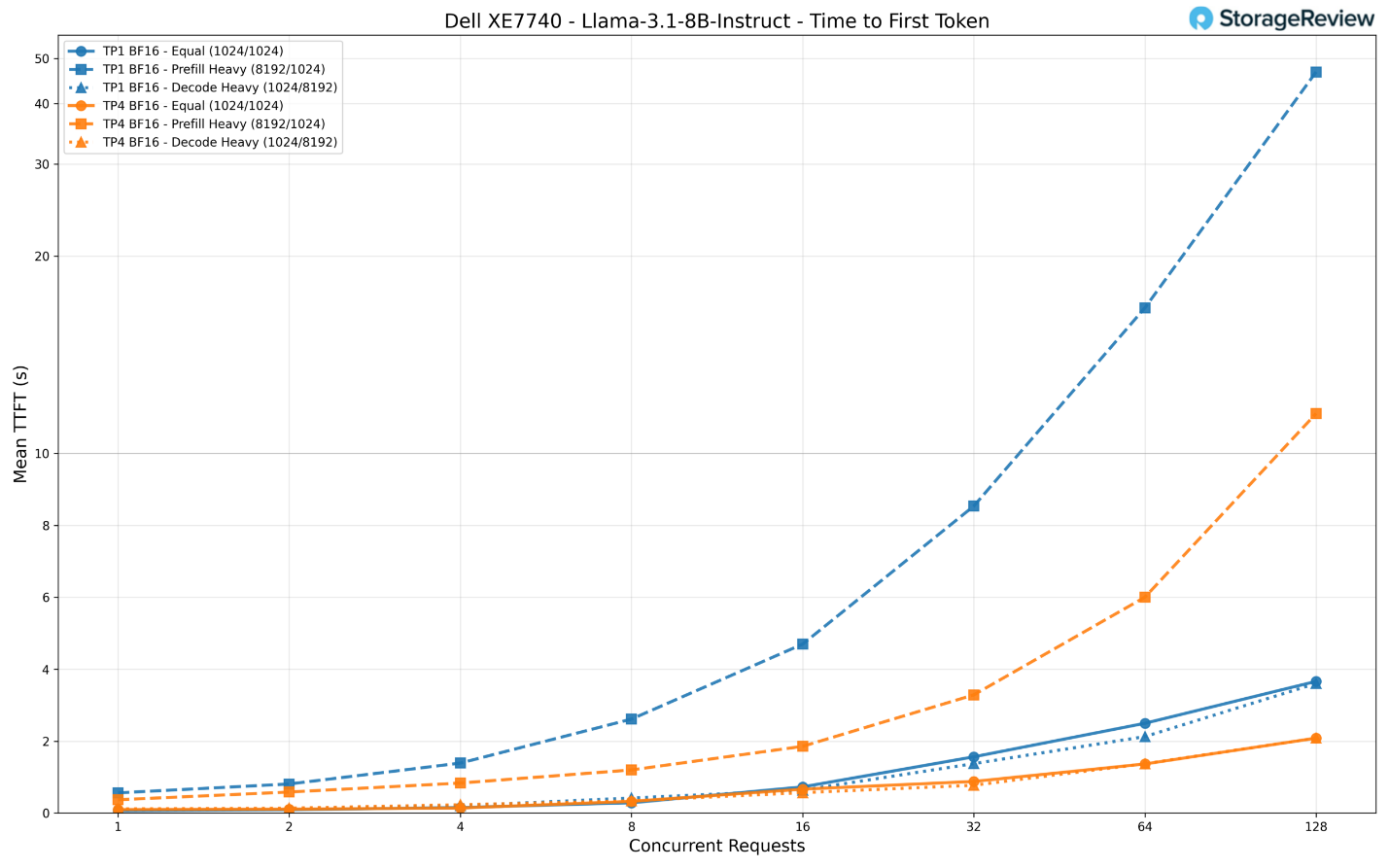
Về độ trễ đối với một người dùng duy nhất, cấu hình TP1 thực tế lại mang lại thời gian phản hồi (TTFT) thấp hơn ở mức yêu cầu thấp (67ms so với 98ms của TP4). Điều này phản ánh chi phí vận hành (overhead) phát sinh khi phải điều phối giữa bốn bộ tăng tốc cho một mô hình vốn dĩ có thể nằm gọn thoải mái trên một card.
Tuy nhiên, khi tải trọng tăng lên, TP4 vượt lên dẫn đầu một cách quyết liệt. Ở mức 128 yêu cầu đồng thời, TP4 duy trì TTFT ở khoảng 2 giây cho các kịch bản tải cân bằng và nặng về giải mã, trong khi TP1 tăng vọt lên lần lượt là 3,7 giây và 6,6 giây. Kịch bản nặng về nạp dữ liệu (prefill-heavy) là nơi khoảng cách trở nên rõ rệt nhất: TP1 đạt tới gần 47 giây TTFT ở 128 yêu cầu, trong khi TP4 giữ mức này ở khoảng 11 giây.
Llama 3.1 70B Instruct Llama 3.1 70B Instruct là mô hình dạng ‘dense’ lớn hơn trong gia đình Llama 3.1 của Meta. Với 70 tỷ tham số, nó mang lại khả năng tuân thủ hướng dẫn và đa ngôn ngữ tốt hơn đáng kể so với biến thể 8B. Các mô hình ở quy mô này rất phù hợp cho các khối lượng công việc dạng đại lý (agentic workloads) chuyên sâu hơn, chẳng hạn như đại diện hỗ trợ khách hàng, trợ lý nghiên cứu đa bước, phân tích tài liệu phức tạp và các tác vụ yêu cầu duy trì ngữ cảnh mạch lạc trong các tương tác dài.
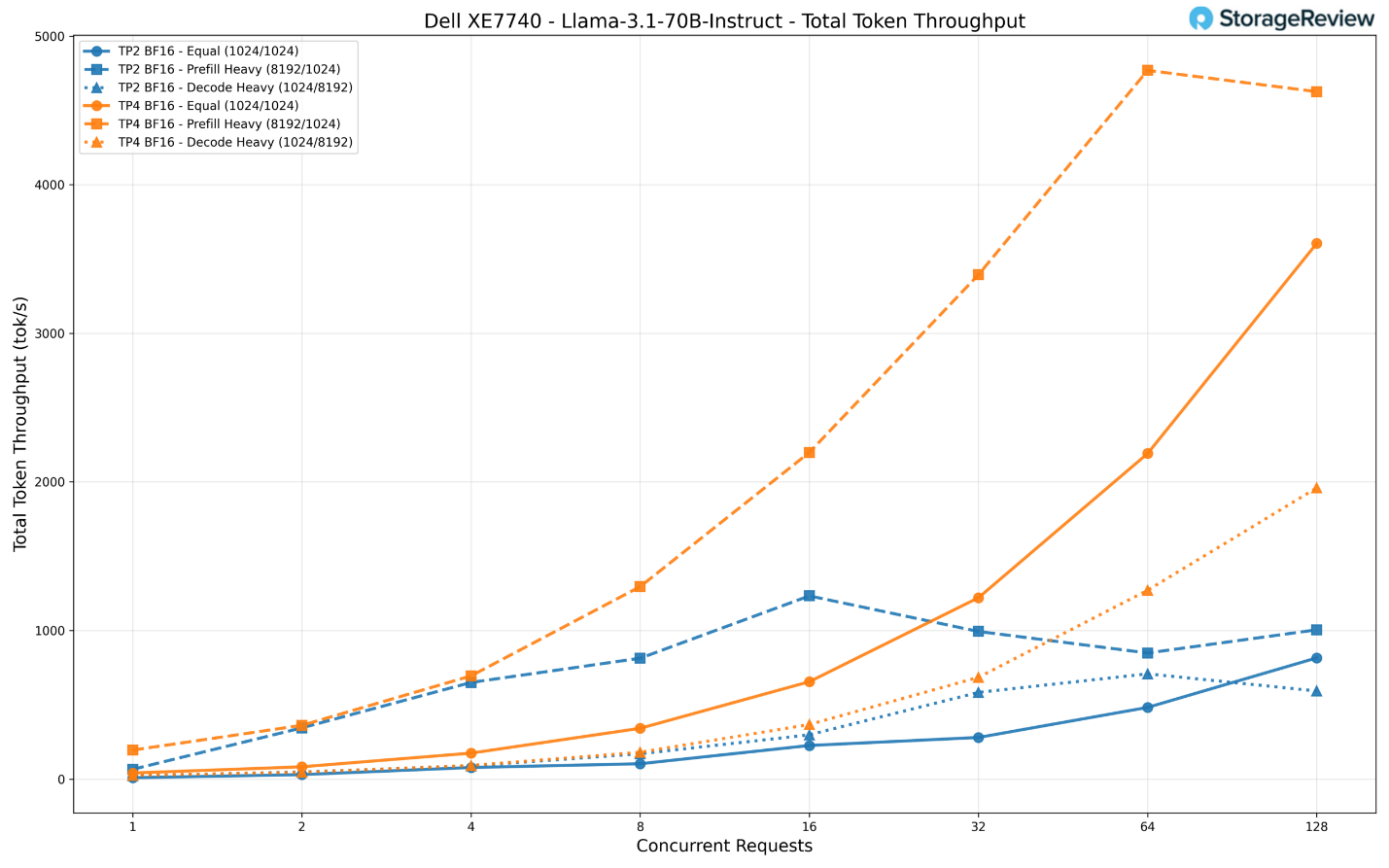
Chúng tôi đã thử nghiệm mô hình này với các cấu hình TP2 (2 bộ tăng tốc) và TP4 (4 bộ tăng tốc). Sự khác biệt về thông lượng giữa hai cấu hình này là cực kỳ lớn.
Ở mức 128 yêu cầu đồng thời, cấu hình TP4 đạt thông lượng khoảng 3.600 token/giây trong kịch bản tải cân bằng và đạt đỉnh gần 4.600 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy). Con số này gấp khoảng 4,4 lần và 4,6 lần so với thông lượng của TP2 (vốn chỉ đạt tối đa khoảng 816 token/giây và 1.005 token/giây tương ứng).
Ngay cả trong kịch bản nặng về giải mã (decode-heavy), TP4 cũng đạt khoảng 1.960 token/giây, so với mức 593 token/giây trên TP2.
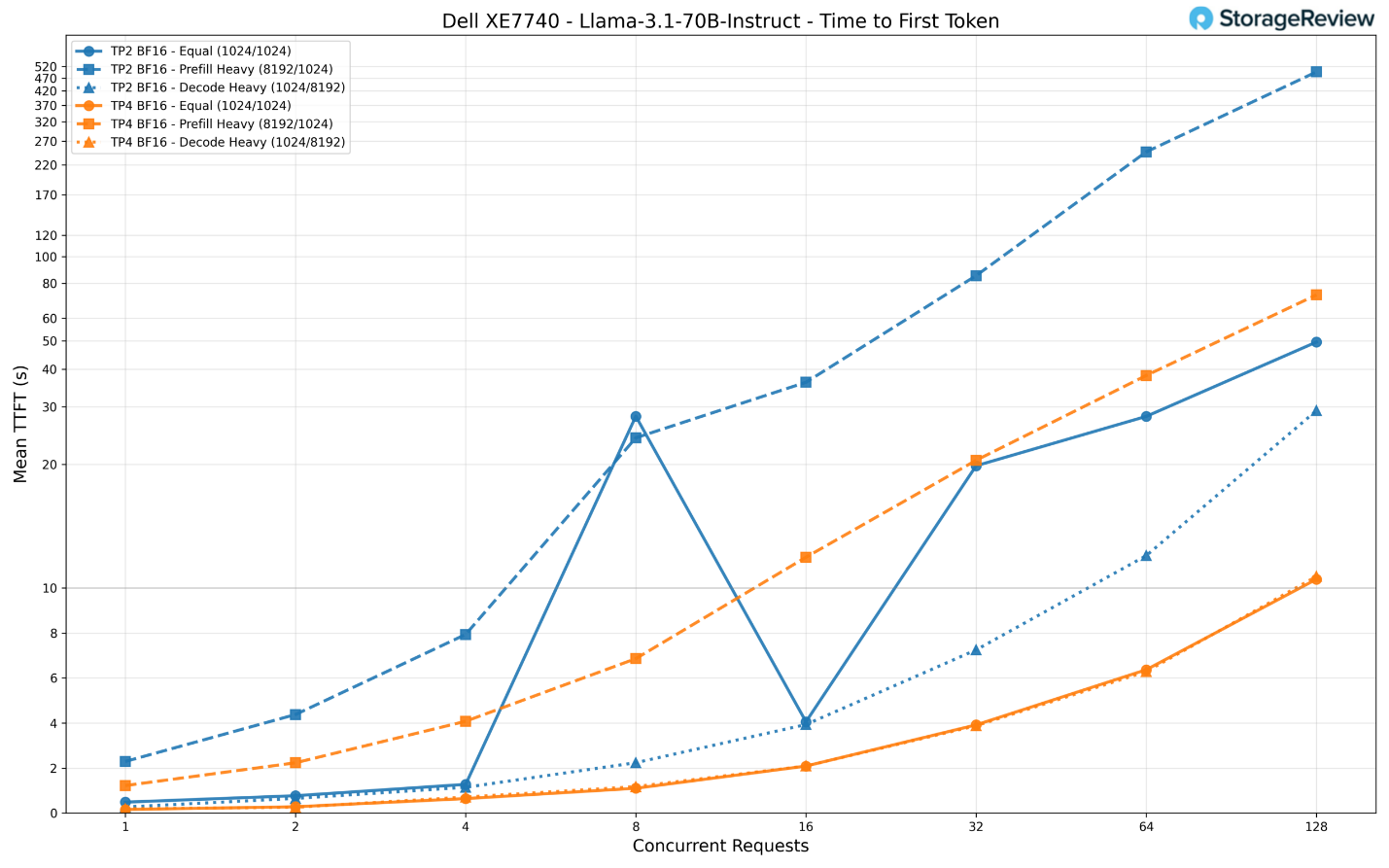
Về thời gian phản hồi (TTFT), cấu hình TP2 (2 card) gặp khó khăn cực độ dưới tải trọng nặng ở kịch bản nạp dữ liệu (prefill-heavy), khi con số này leo thang tới mức kinh khủng là 496 giây (hơn 8 phút) với 128 yêu cầu đồng thời, khiến nó về cơ bản là không thể sử dụng cho các ứng dụng tương tác. TP4 giúp giảm mức này xuống còn khoảng 73 giây. Đối với các kịch bản cân bằng và nặng về giải mã, TP4 duy trì TTFT ở khoảng 10 giây, trong khi TP2 lần lượt chạm mức 50 và 29 giây. Ở mức yêu cầu thấp, TP4 phản hồi token đầu tiên chỉ trong khoảng 160ms, so với 486ms trên TP2.
Qwen3 Coder 30B-A3B Instruct Qwen3 Coder 30B-A3B là một trong những mô hình lập trình phổ biến nhất cho việc triển khai suy luận cục bộ và sử dụng kiến trúc Hỗn hợp các chuyên gia (Mixture-of-Experts – MoE). Khác với các mô hình ‘dense’ (nơi mọi tham số đều tham gia vào mỗi lượt xử lý), các mô hình MoE định tuyến mỗi token qua một nhóm nhỏ các mạng chuyên gia chuyên biệt.
Dòng Qwen3 Coder này duy trì kích thước toàn bộ mô hình là 30 tỷ tham số ở độ chính xác BF16, nhưng chỉ kích hoạt 3 tỷ tham số cho mỗi token được tạo ra. Kiểu kích hoạt thưa thớt này giúp mô hình mang lại chất lượng của một mạng lưới lớn hơn nhiều trong khi chỉ yêu cầu một phần nhỏ sức mạnh tính toán trên mỗi token. Điều này khiến nó cực kỳ hiệu quả trên các phần cứng hỗ trợ tốt việc điều phối dữ liệu (routing overhead). Đối với người dùng cuối, mô hình này rất phù hợp cho hỗ trợ lập trình hàng ngày như tạo mã mẫu (boilerplate), hoàn thiện hàm, giải thích mã nguồn và viết kiểm thử đơn vị (unit tests).
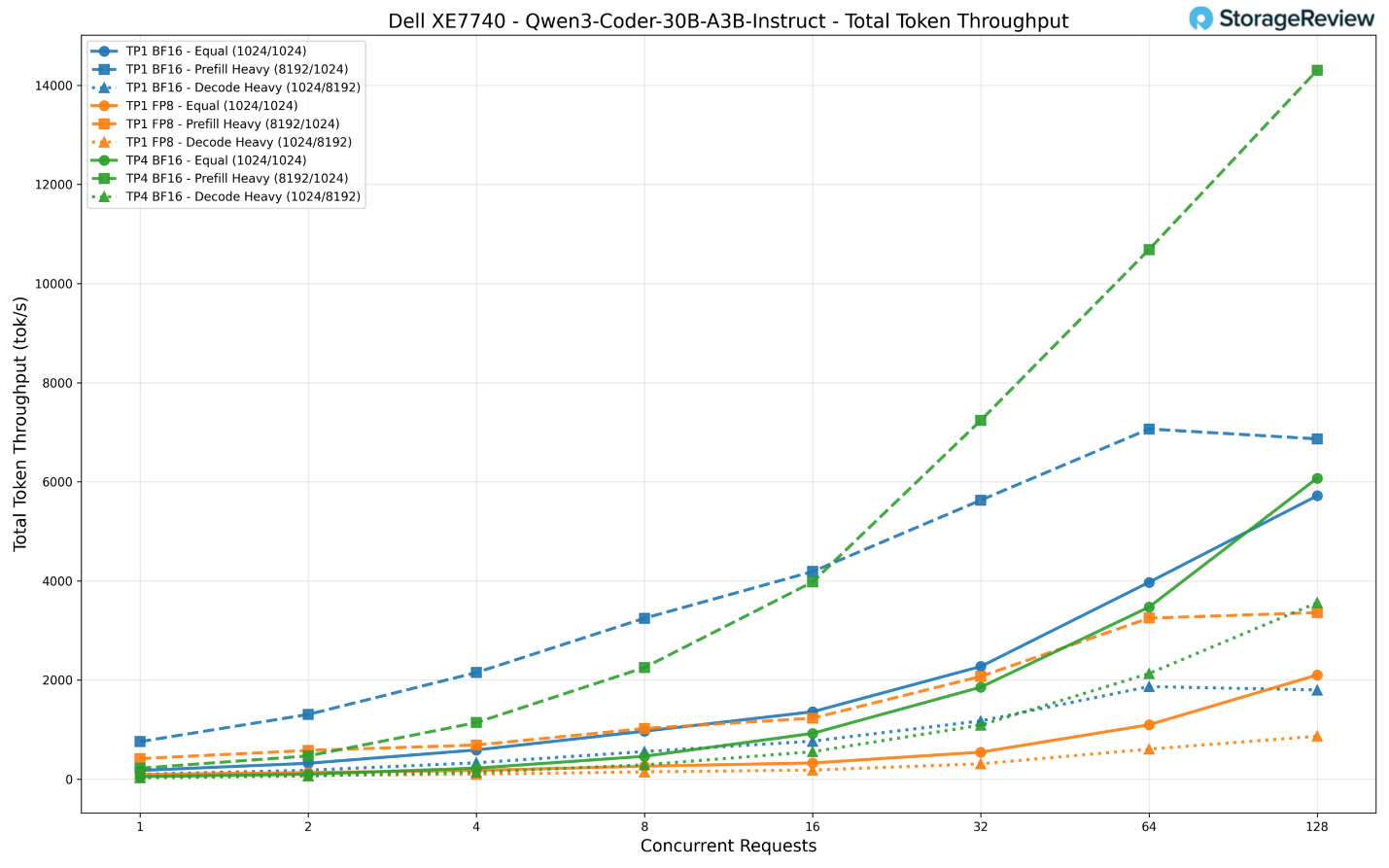
Chúng tôi đã thử nghiệm ba cấu hình: TP1 BF16, TP1 FP8, và TP4 BF16. Ở mức 128 yêu cầu đồng thời, cấu hình TP4 BF16 dẫn đầu nhóm với thông lượng khoảng 14.300 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy) — đây cũng là con số thông lượng cao nhất mà chúng tôi ghi nhận được trên tất cả các mô hình trong bộ thử nghiệm này.
Tiếp theo là TP1 BF16 với khoảng 6.900 token/giây trong cùng kịch bản, trong khi TP1 FP8 tụt lại phía sau ở mức khoảng 3.360 token/giây. Trong kịch bản tải cân bằng (equal workload), khoảng cách có phần hẹp lại với TP4 đạt 6.073 token/giây, TP1 BF16 đạt 5.718 token/giây và TP1 FP8 đạt 2.101 token/giây.
Như đã thảo luận trong phần lưu ý về FP8 ở trên, các con số thấp hơn của FP8 ở đây phản ánh tình trạng hiện tại của phiên bản vLLM do Intel phát triển hơn là do nghẽn cổ chai về phần cứng.
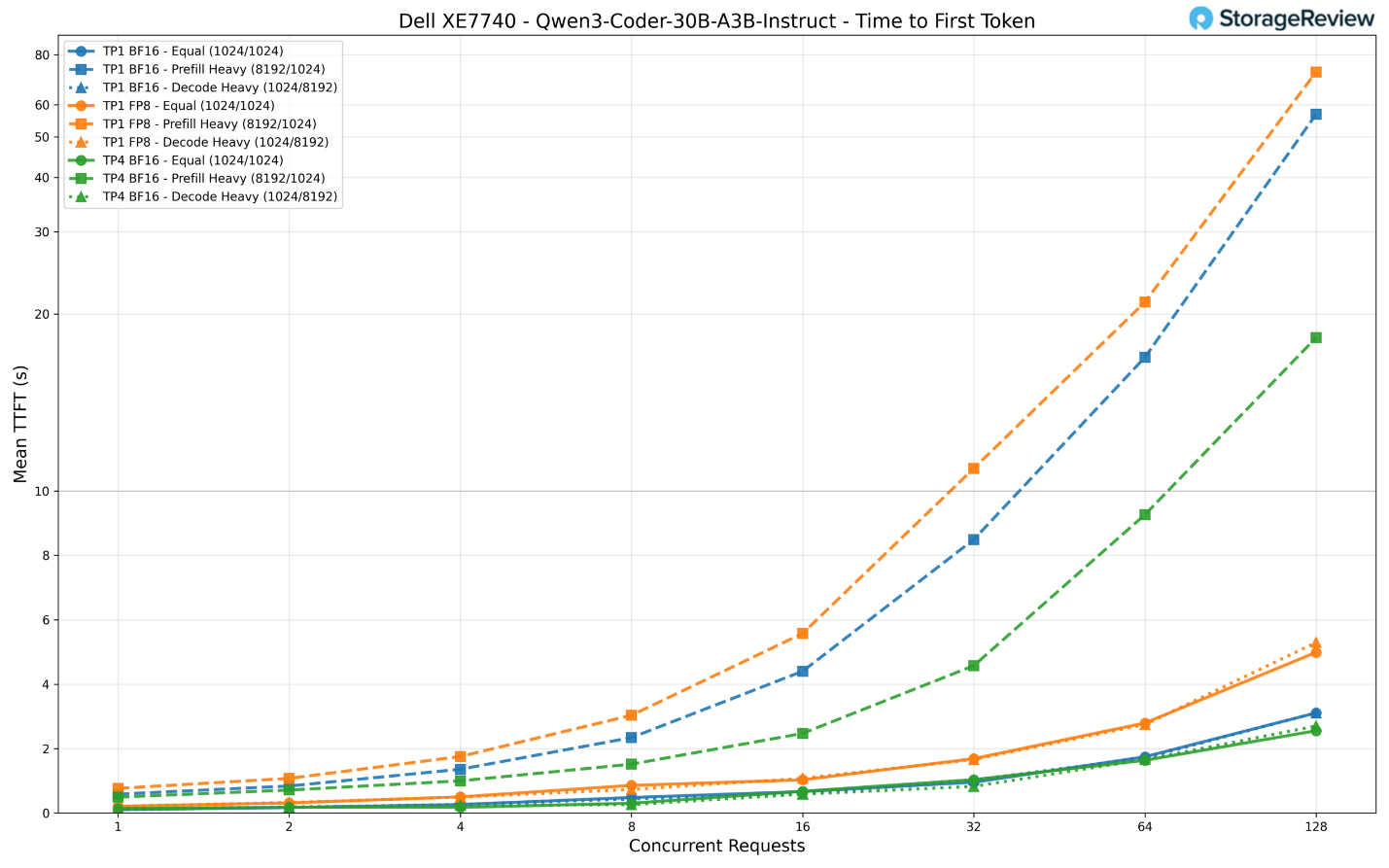
Chỉ số TTFT (thời gian phản hồi đầu tiên) được duy trì ở mức thấp nhờ vào kiểu kích hoạt thưa thớt (sparse activation). Cấu hình TP4 BF16 mang lại độ trễ token đầu tiên khoảng 140ms khi chỉ có một người dùng và giữ ở mức khoảng 2,6 giây với 128 yêu cầu đồng thời trong kịch bản tải cân bằng.
TP1 BF16 có kết quả tương đương ở mức yêu cầu thấp (106ms) nhưng tăng lên 3,1 giây khi chịu tải tối đa. Kịch bản nặng về nạp dữ liệu (prefill-heavy) một lần nữa phân hóa rõ rệt các cấu hình: TP4 đạt khoảng 18 giây với 128 yêu cầu, trong khi TP1 BF16 chạm mức 57 giây và TP1 FP8 kéo dài tới 72 giây.
Qwen3 235B-A22B Thinking Là mô hình lớn nhất trong bộ thử nghiệm của chúng tôi, Qwen3 235B-A22B Thinking là một mô hình suy luận MoE khổng lồ với tổng cộng 235 tỷ tham số và 22 tỷ tham số kích hoạt cho mỗi token.
Vượt xa quy mô thông thường, mô hình này tích hợp sẵn khả năng suy luận chuỗi suy nghĩ (Chain-of-Thought – CoT), cho phép nó chia nhỏ các vấn đề phức tạp theo từng bước trước khi đưa ra câu trả lời cuối cùng (đổi lại là tốn nhiều token giải mã hơn). Điều này khiến nó đặc biệt phù hợp cho các nhiệm vụ khó khăn nhất: tạo mã nguồn nâng cao và gỡ lỗi, giải toán, suy luận logic đa bước và các quy trình đại lý (agentic) phức tạp nơi độ chính xác quan trọng hơn tốc độ thuần túy. Mô hình này bắt buộc phải chạy trên cấu hình TP4 (4 card) và chúng tôi đã thử nghiệm nó ở cả hai độ chính xác BF16 và FP8.
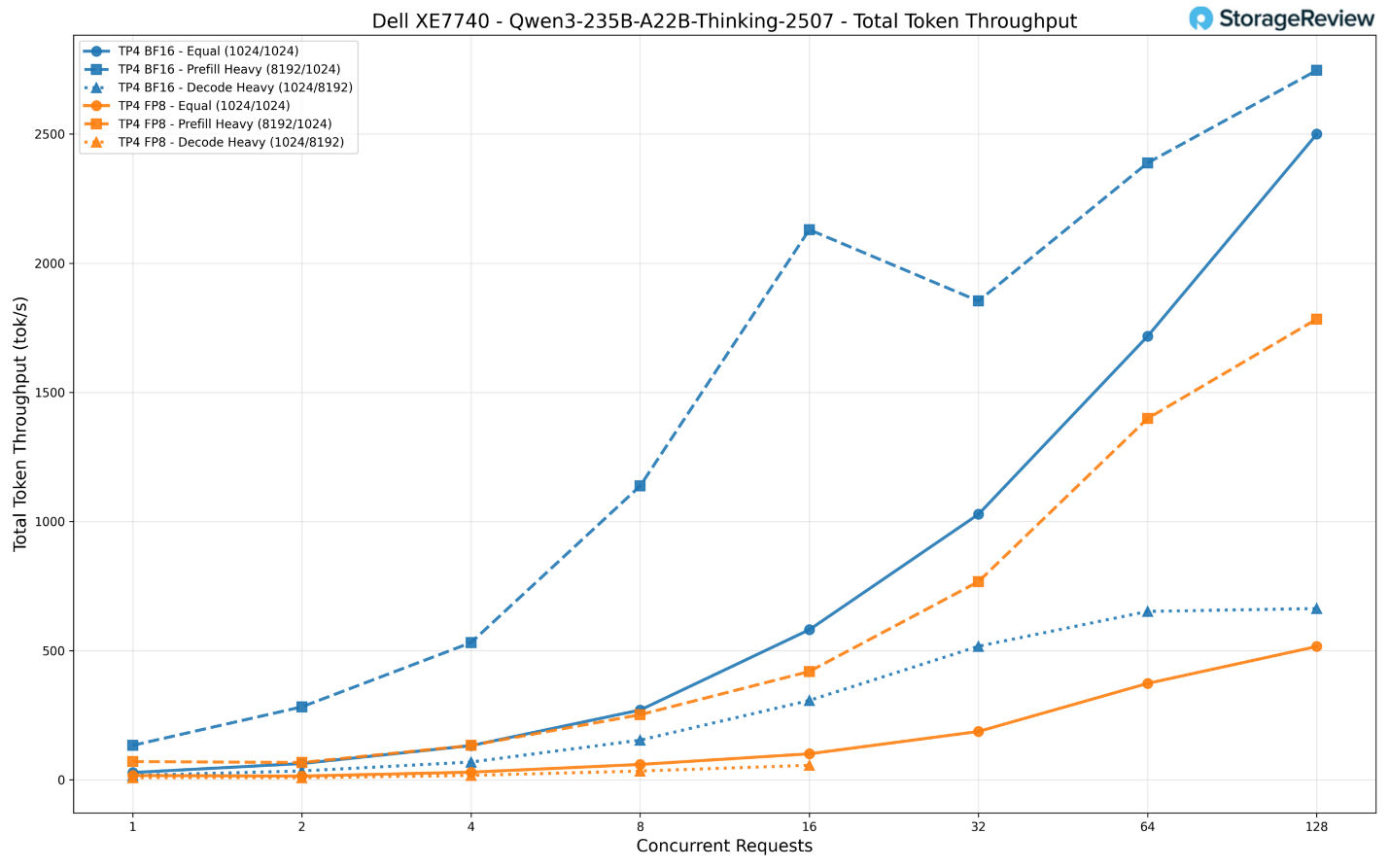
BF16 rõ ràng vượt trội hơn FP8 trên mọi phương diện. Ở mức 128 yêu cầu đồng thời, định dạng BF16 đạt thông lượng xấp xỉ 2.750 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy) và 2.500 token/giây trong kịch bản cân bằng.
Trong khi đó, định dạng FP8 chỉ đạt lần lượt khoảng 1.784 token/giây và 516 token/giây. Biến thể FP8 thậm chí còn gặp hiện tượng quá hạn thời gian (timeout) trong kịch bản nặng về giải mã (decode-heavy) ở các mức yêu cầu đồng thời cao (từ 32 yêu cầu trở lên).
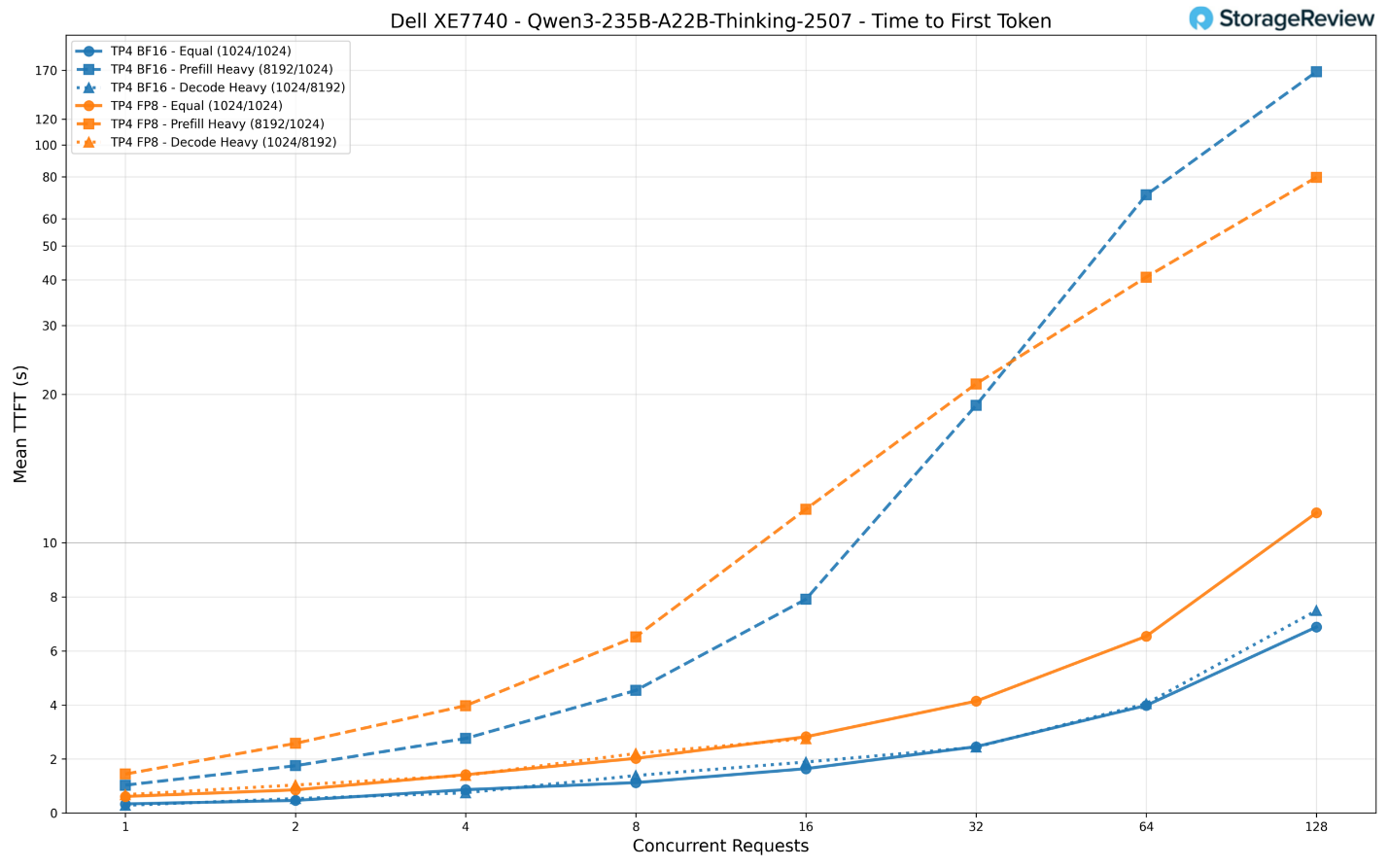
Về thời gian phản hồi (TTFT), định dạng BF16 bắt đầu ở mức khoảng 340ms cho một yêu cầu cân bằng duy nhất và tăng lên xấp xỉ 6,9 giây với 128 yêu cầu đồng thời. Đây là mức phản hồi khá tốt cho một mô hình ở quy mô khổng lồ này.
Định dạng FP8 chậm hơn khoảng 2 lần trong suốt quá trình thử nghiệm, bắt đầu ở mức 615ms và chạm ngưỡng 11,2 giây khi chịu tải tối đa. Kịch bản nặng về nạp dữ liệu (prefill-heavy) là thử thách khắc nghiệt nhất, với BF16 tăng lên 168 giây và FP8 lên 80 giây ở mức 128 yêu cầu.
Giải pháp này dành cho ai? Nhu cầu về suy luận AI (Inference) không hề có dấu hiệu chậm lại. Dù các tổ chức đang triển khai mô hình nội bộ để hỗ trợ các đội ngũ lập trình viên, tích hợp AI vào các sản phẩm dành cho khách hàng, hay thiết lập các quy trình tự động hóa chạy 24/7, yêu cầu về năng lực tính toán vẫn liên tục tăng cao.
Và đi kèm với nhu cầu đó là một “nút thắt cổ chai” quen thuộc: Khâu mua sắm. Thời gian chờ đợi (lead times) để có được các bộ tăng tốc phổ biến nhất (như của NVIDIA) có thể kéo dài hàng tháng trời, làm đình trệ các dự án vốn đã được cấp vốn và bố trí nhân sự.
Đoạn kết này nhấn mạnh vào tính sẵn có, sự linh hoạt và giá trị thực tiễn của Dell PowerEdge XE7740 trong bối cảnh thị trường AI đang cực kỳ khan hiếm phần cứng.
Bản dịch:
“Máy chủ XE7740, khi được cấu hình với Intel Gaudi 3, đã giải quyết trực tiếp các hạn chế về nguồn cung. Các bộ tăng tốc Gaudi 3 hiện đã sẵn hàng, và Intel cung cấp các mẫu triển khai đã được xác thực để các đội ngũ kỹ thuật có thể đi từ khâu mở hộp đến phục vụ suy luận chỉ trong vài giờ.
Dell còn hạ thấp rào cản hơn nữa bằng các chương trình ‘dùng thử trước khi mua’ (try-and-buy), cho phép đặt hệ thống XE7740 trực tiếp vào môi trường của bạn. Điều này giúp bạn kiểm chứng hiệu năng thực tế dựa trên khối lượng công việc, dữ liệu và hạ tầng hiện có trước khi quyết định triển khai chính thức. Sự kết hợp giữa khả năng cung ứng tức thì, thời gian tạo ra giá trị nhanh chóng và đánh giá rủi ro thấp khiến cấu hình Gaudi 3 trở nên đặc biệt hấp dẫn đối với các tổ chức cần năng lực suy luận ngay hôm nay và không thể chờ đợi trong các hàng đợi cấp phát linh kiện.
Tuy nhiên, XE7740 không phải là nền tảng chỉ dành cho một loại bộ tăng tốc duy nhất. Với cam kết của Dell về sự đa dạng hóa silicon, cùng một nền tảng này có thể đi kèm với nhiều tùy chọn bộ tăng tốc phổ biến nhất trên thị trường, và lựa chọn đúng đắn hoàn toàn phụ thuộc vào khối lượng công việc. Ví dụ, các luồng xử lý video là sự lựa chọn tự nhiên cho NVIDIA L4, và XE7740 có thể trang bị tới 16 GPU L4 cùng với 8 khe cắm NIC PCIe Gen5 x16 để tạo nên một hệ thống truyền phát và chuyển mã video không có đối thủ. Các tổ chức chạy hỗn hợp các khối lượng công việc AI giữa các phòng ban có thể tiêu chuẩn hóa trên khung máy (chassis) XE7740 và chỉ cần thay đổi cấu hình bộ tăng tốc cho phù hợp với từng nhiệm vụ, giúp đơn giản hóa việc quản lý đội ngũ máy chủ trong khi vẫn tối ưu hóa tính toán cho từng tác vụ cụ thể.
Kết luận Dell PowerEdge XE7740 được thiết kế cho thực tế suy luận của doanh nghiệp. Thiết kế nhiệt hai vùng, sơ đồ PCIe có cấu trúc, kiến trúc bộ nhớ băng thông cao và khả năng kết nối mạng mở rộng tạo nên một hệ thống được xây dựng cho các khối lượng công việc sản xuất bền bỉ. Đây không phải là những lựa chọn thiết kế ngẫu nhiên; chúng phản ánh một mô hình hạ tầng nơi việc suy luận chạy liên tục, mở rộng theo dự đoán và tích hợp sạch sẽ vào các hoạt động trung tâm dữ liệu hiện có.
Trong bài đánh giá này, Intel Gaudi 3 đã chứng minh rằng XE7740 mang lại khả năng suy luận mạnh mẽ ngay hôm nay trên cả kiến trúc ‘dense’ và MoE, với khả năng mở rộng dự đoán được và thông lượng bị giới hạn bởi bộ nhớ (memory-bound throughput) rất ấn tượng. Các tối ưu hóa phần mềm sẽ tiếp tục được cải thiện, nhưng nền tảng kiến trúc của hệ thống này đã thực sự vững chắc.

Quan trọng hơn cả, PowerEdge XE7740 đã thiết lập một mô hình chuẩn mực và bền vững cho hạ tầng AI doanh nghiệp. Các tổ chức giờ đây có thể chuẩn hóa hệ thống dựa trên một khung máy (chassis), quy trình quản lý và mô hình triển khai đồng nhất, trong khi vẫn có thể linh hoạt thay đổi chiến lược sử dụng bộ tăng tốc (GPU/Accelerators) theo thời gian.
Khi các mô hình AI ngày càng lớn mạnh, khối lượng công việc trở nên đa dạng và quá trình suy luận (inference) dần trở thành một phần cốt lõi trong vận hành kinh doanh, thì nhu cầu về một hạ tầng ổn định và có khả năng thích ứng cao sẽ ngày càng gia tăng. PowerEdge XE7740 được ra đời để đón đầu xu thế đó. Nó mang lại sự cân bằng về kiến trúc, sự tối ưu trong vận hành và không gian mở rộng cần thiết để đưa AI doanh nghiệp từ giai đoạn ‘áp dụng nhanh chóng’ sang giai đoạn ‘tích hợp dài hạn
n khai mô hình để phục vụ người dùng, xử lý dữ liệu thực và tạo ra giá trị kinh doanh đo lường được. Dell PowerEdge XE7740 được thiết kế rõ ràng để dành cho thế giới thứ hai này.

Những điểm nhấn chính
PowerEdge XE7740 được xây dựng chuyên biệt cho tác vụ suy luận (inference) doanh nghiệp: Với thiết kế tản nhiệt hai vùng, cấu trúc sơ đồ PCIe Gen5 tối ưu và khả năng kết nối mạng mở rộng (scale-out), máy chủ này hoàn toàn tương thích với các khối lượng công việc thực tế trongmôi trường sản xuất.
Sự cân bằng hệ thống có tính toán: Kết hợp mật độ nhân xử lý cao của dòng chip Xeon 6, băng thông bộ nhớ lớn và chuẩn lưu trữ PCIe Gen5 E3.S NVMe để hỗ trợ hiệu quả việc giải phóng bộ nhớ đệm KV (KV cache offload) và điều phối hệ thống.
Tính linh hoạt về phần cứng là nền tảng: Hỗ trợ đa dạng các bộ tăng tốc chuẩn PCIe Gen5, giúp doanh nghiệp có nhiều lựa chọn về chip xử lý mà không buộc phải thiết kế lại toàn bộ hạ tầng.
Khả năng mở rộng liền mạch theo thời gian: Hệ thống có thể nâng cấp linh hoạt, từ việc lắp đặt một phần số lượng GPU trong một khung máy đơn lẻ cho đến việc triển khai suy luận phân tán trên toàn bộ tủ rack nhờ vào 8 khe cắm mạng chuyên dụng PCIe Gen5 x16 ở phía sau.
Cốt lõi của XE7740 là cam kết về sự đa dạng của các dòng chip xử lý (silicon diversity). Thay vì đóng khung nền tảng vào một lộ trình bộ tăng tốc duy nhất, Dell đã xây dựng một hệ thống có khả năng thích ứng với nguồn cung, chi phí và mức độ sẵn sàng của từng tổ chức. XE7740 hỗ trợ hàng loạt bộ tăng tốc PCIe Gen5, bao gồm các dòng GPU của NVIDIA như RTX PRO 6000, H100/200, L40S, L4 và A16 dành cho các tổ chức coi trọng khả năng tương thích hệ sinh thái rộng rãi; đồng thời hỗ trợ Intel Gaudi 3 cho các đội ngũ tìm kiếm một lộ trình suy luận tiết kiệm chi phí và dễ tiếp cận hơn. Các bộ tăng tốc Gaudi 3 hiện đã sẵn hàng, cho phép các tổ chức chuyển từ giai đoạn lập kế hoạch sang triển khai thực tế mà không gặp phải sự chậm trễ trong khâu thu mua vốn thường ảnh hưởng đến chiến lược trang bị bộ tăng tốc.
Khi suy luận (inference) trở thành khối lượng công việc AI chiếm ưu thế, thì tính sẵn có và cấu trúc chi phí trở nên cực kỳ quan trọng. Hầu hết các doanh nghiệp không huấn luyện các mô hình quy mô tiên phong; họ đang vận hành các luồng suy luận, phục vụ các mô hình ngôn ngữ quy mô trung bình, thực hiện quy trình tạo phản hồi tăng cường tra cứu (RAG) và triển khai thị giác máy tính vào sản xuất. Trong bối cảnh đó, Gaudi 3 được định vị là một trong những bộ tăng tốc suy luận hiện đại có giá thành hợp lý nhất trên thị trường, cung cấp kiến trúc tân tiến với bộ nhớ băng thông cao và khả năng mở rộng dựa trên Ethernet mà không tốn kém như các dòng GPU hàng đầu chuyên dùng cho huấn luyện. Trong hệ thống XE7740, Gaudi 3 không nhằm mục đích thay thế hoàn toàn mà tập trung vào việc hiện thực hóa các hoạt động triển khai suy luận bền vững.
Nền tảng bao quanh các bộ tăng tốc cũng được thiết kế kỹ lưỡng không kém. XE7740 được xây dựng trên bộ vi xử lý Intel Xeon 6, và trong các hệ thống tập trung vào suy luận, CPU vẫn là một thành phần then chốt. Số lượng nhân lớn và băng thông bộ nhớ tăng cao cung cấp mức tài nguyên dự phòng cần thiết cho các tác vụ lập lịch, phân tách từ (tokenization), tiền xử lý và điều phối—vốn nằm trực tiếp trên lộ trình xử lý quan trọng của suy luận. Ổ lưu trữ E3.S NVMe gắn phía trước hỗ trợ đắc lực cho việc chuẩn bị dữ liệu cục bộ và giải phóng bộ nhớ đệm KV (KV cache offload), giúp giảm tải cho bộ tăng tốc và cải thiện hiệu suất tổng thể của hệ thống. Thiết kế cân bằng này phản ánh một sự hiểu biết sâu sắc rằng: hiệu năng suy luận được định hình bởi toàn bộ hệ thống chứ không chỉ riêng bộ tăng tốc.

XE7740 cũng được thiết kế để có khả năng mở rộng linh hoạt theo thời gian. Các tổ chức có thể bắt đầu với cấu hình vừa phải — ví dụ như hai hoặc bốn bộ tăng tốc (accelerators) — để khai thác giá trị ngay lập tức mà không cần lắp đầy toàn bộ khung máy (chassis). Khi nhu cầu tăng lên, chính nền tảng này có thể mở rộng theo chiều dọc hoặc chuyển đổi sang mô hình suy luận phân tán (distributed inference).
Tám khe cắm PCIe Gen5 x16 ở mặt sau cung cấp băng thông chuyên dụng cho kết nối mạng tốc độ cao, cho phép XE7740 đóng vai trò như một khối cấu trúc (building block) để thiết lập các cụm suy luận mở rộng (scale-out clusters). Ngoài ra, tùy chọn hỗ trợ DPU giúp gia tăng tính linh hoạt bằng cách đảm nhận các tác vụ mạng và truyền thông khi hệ thống vận hành đi vào giai đoạn ổn định.
Thông số kĩ thuật: Dell PowerEdge XE7740
| Specification | PowerEdge XE7740 |
|---|---|
| Features of PowerEdge XE7740 | |
| Processor | Two Intel® Xeon® 6 series processors, with up to 86 cores per processor |
| Slots | |
| PCIe Accelerators | 8x PCIe Gen 5 x16 DW-FHFL up to 600 W, or
16x PCIe Gen 5 x16 SW-FHFL up to 75 W |
| PCIe NICs |
|
| Form factor | |
| Form factor | 4U rack server |
| Memory | |
| DIMM speed, maximum capacity | Up to 6400 MT/s, 4 TB max |
| Memory module slots | 32 DDR5 DIMM slots Supports registered ECC DDR5 RDIMM only. |
| Storage | |
| Front bays | Up to 8 x EDSFF E3.S Gen5 NVMe (SSD) max 122.88 TB |
| Storage controllers | |
| Internal boot | Boot Optimized Storage Subsystem (BOSS-N1 DC-MHS): HWRAID 1, 2 x M.2
NVMe SSDs |
| Power supply | |
| Power supply | 3200 W Titanium 200-240 V AC or 240 V DC, hot swap redundant
Multi-capacity for 3200 W PSU:
Multi-capacity for 2400 W PSU:
CAUTION: The system requires at least one PSU in the CPU zone and one PSU in the GPU zone to maintain BMC and standby power. If the GPU zone has no PSU installed, then the system will remain on hold. To ensure full redundancy, install N+N PSUs in each zone: 1+1 in the CPU zone and 3+3 in the GPU zone. Removing all PSUs from the CPU zone while the system is powered on will cause an immediate shutdown and may result in data loss. |
| Cooling Options | |
| Cooling Options | Air Cooling |
| Fans | Up to four sets of high-performance (HPR) platinum-grade fans (dual fan module) installed in the mid tray
Up to twelve high-performance (HPR) platinum-grade fans installed on the front of the system All are hot-swap fans |
| Ports | |
| Network options | 1 PCIe Gen 5 OCP 3.0 Compatible I/O (supported by x8 PCIe lanes) |
| Front ports | 1 x USB 2.0 Type-A (optional) 1 x Mini-Display port (optional) 1 x USB 2.0 Type-C dual mode (Host/iDRAC Direct port) |
| Rear ports | 1 x Dedicated iDRAC/BMC Direct Ethernet port 2 x USB 3.1 Type A port 1 x VGA |
| Internal ports | 1 x USB 3.1 Type-A |
Thiết kế và Cấu trúc của XE7740
Kiến trúc Hai vùng (Dual-Zone): Tách biệt CPU và GPU
Một trong những lựa chọn thiết kế đặc trưng nhất của XE7740 là việc phân tách vật lý thành hai vùng nhiệt và năng lượng riêng biệt.
- Vùng CPU: Chiếm phần không gian 1U phía trên, bao gồm cả hai bộ xử lý Xeon 6, toàn bộ 32 khe cắm DIMM, hệ thống lưu trữ và mô-đun quản lý DC-SCM. Vùng CPU này sử dụng bốn bộ mô-đun quạt kép hiệu suất cao (kích thước 40×40×56mm), cung cấp lưu lượng không khí lên đến 47.4 CFM.

Phần 3U bên dưới là vùng GPU, nơi chứa toàn bộ các khe cắm bộ tăng tốc với cơ sở hạ tầng làm mát chuyên dụng riêng, cùng với Bo mạch nền PCIe (PBB), các khe cắm mở rộng PCIe hướng ra phía sau và kết nối OCP NIC.
Vùng GPU sử dụng mười hai quạt hiệu suất cao loại lớn (kích thước 60×60×56mm) với công suất lưu lượng gió lên đến 122.2 CFM mỗi quạt—cao hơn đáng kể so với quạt ở vùng CPU. Tất cả các quạt đều có khả năng thay thế nóng (hot-swappable).
Cách làm mát hai vùng này giúp đảm bảo rằng nhu cầu tản nhiệt cực lớn từ các bộ tăng tốc có chỉ số TDP cao (lên đến 600W mỗi card) sẽ không gây ảnh hưởng đến hiệu quả làm mát của CPU và bộ nhớ, và ngược lại, ngay cả khi lắp đặt trong tủ rack 19-inch tiêu chuẩn.

Dell đã dành sự quan tâm đặc biệt đến việc tối ưu hóa luồng không khí bên trong XE7740. Các hệ thống có mật độ bộ tăng tốc cao vốn dĩ đòi hỏi lượng lớn dây cáp nội bộ, bao gồm dây cấp nguồn phụ cho GPU, cáp tín hiệu PCIe giữa bo mạch HPM và bo mạch nền PBB, cùng các kết nối bảng mạch quạt.
Trong XE7740, các loại cáp này được đi dọc theo vách ngăn của khung máy bằng các giá đỡ cố định và hệ thống nắp đậy cáp chuyên dụng. Mỗi sợi cáp đều được chế tạo với độ dài chính xác theo yêu cầu; hoàn toàn không có tình trạng dư thừa các bó dây bên trong hệ thống. Bằng cách loại bỏ dây cáp khỏi kênh dẫn khí trung tâm, thiết kế này duy trì được một đường lưu thông không khí thông suốt từ trước ra sau và giảm thiểu tối đa lực cản (trở lực) trên cả hai vùng làm mát CPU và GPU.

Trong một bộ khung máy chủ (chassis) chứa tới tám bộ tăng tốc (GPU/Accelerator) với công suất 600W mỗi chiếc, ngay cả những vật cản nhỏ nhất trên đường đi của luồng khí cũng có thể tạo ra các điểm nóng cục bộ. Điều này buộc hệ thống quạt phải đẩy tốc độ vòng quay lên cao hơn — dẫn đến việc tăng cả mức tiêu thụ điện năng lẫn tiếng ồn phát ra.
Phương pháp quản lý cáp của Dell được thiết kế để giữ cho khu vực trung tâm của thân máy luôn thông thoáng, giúp luồng khí lưu thông trực tiếp và không bị cản trở tới các linh kiện tỏa nhiệt nhiều nhất, đảm bảo hiệu quả làm mát tối ưu.
Cấu trúc liên kết PCIe và luồng dữ liệu
Hệ thống con PCIe của XE7740 được xây dựng xung quanh bốn bộ chuyển mạch (switch) PCIe Gen 5 trên bo mạch nền PCIe (PBB), được ký hiệu từ SW1 đến SW4. Các bộ chuyển mạch này đóng vai trò là xương sống cho kiến trúc I/O của hệ thống, kết nối các bộ tăng tốc (GPU), mạng và lưu trữ với hai bộ xử lý Xeon 6 theo một cấu trúc liên kết được tổ chức chặt chẽ.
16 khe cắm GPU nội bộ được chia thành hai nhóm (mỗi nhóm 8 khe), mỗi nhóm được phục vụ bởi một cặp bộ chuyển mạch PCIe, và mỗi bộ chuyển mạch lại kết nối ngược dòng (upstream) tới một CPU. Trong mỗi nhóm, các cặp khe cắm GPU độ rộng kép (double-width) nằm kề nhau được bố trí xen kẽ giữa hai bộ chuyển mạch:
- Về phía CPU0: SW1 phục vụ các khe GPU 21 và 25, cùng các khe PCIe phía sau 8 và 9; trong khi SW2 phục vụ các khe GPU 23 và 27, cùng các khe PCIe phía sau 6 và 7.
- Về phía CPU1: SW3 phục vụ các khe GPU 29 và 33, cùng các khe PCIe phía sau 3 và 4; trong khi SW4 phục vụ các khe GPU 31 và 35, cùng các khe PCIe phía sau 1 và 2.
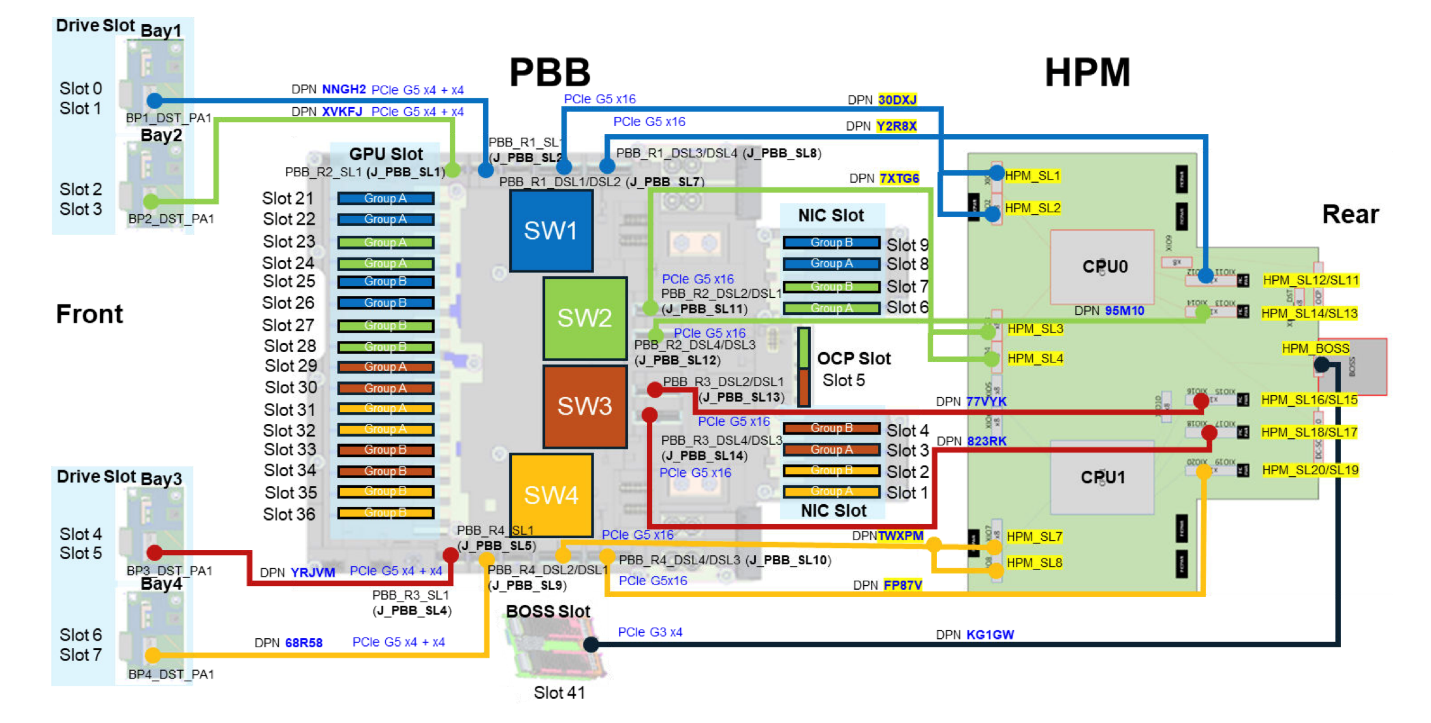
Do đó, mỗi phân vùng CPU (CPU domain) sở hữu: bốn khe cắm bộ tăng tốc (accelerator) độ rộng kép, bốn khe cắm NIC/I/O phía sau, và bốn trong số tám khoang lưu trữ NVMe E3.S ở mặt trước.
Cấu trúc chuyển mạch (switch topology) này có ý nghĩa quan trọng đối với luồng dữ liệu, đặc biệt là lưu lượng dựa trên giao thức RDMA. Vì mỗi bộ chuyển mạch (switch) quản lý cả các khe cắm bộ tăng tốc và các khe cắm card mạng (NIC) phía sau, nên một bộ tăng tốc và một bộ thích nghi mạng (network adapter) nằm trên cùng một switch có thể thực hiện truyền dữ liệu RDMA hoàn toàn bên trong cấu trúc của switch đó.
Dữ liệu không bao giờ cần phải đi qua tổ hợp gốc (root complex) của CPU, từ đó loại bỏ được ‘vùng đệm trung gian’ (CPU bounce buffer) – thứ vốn dĩ bắt buộc phải có khi một thiết bị PCIe ở cổng gốc này muốn giao tiếp với một thiết bị ở cổng gốc khác. Điều này giúp giảm độ trễ, tránh tiêu tốn băng thông bộ nhớ quý giá của CPU và giải phóng các chu kỳ xử lý của CPU cho những tác vụ khác.

Việc giao tiếp bên trong một phân vùng CPU duy nhất — giữa hai bộ chuyển mạch (switch) của nó — sẽ định tuyến thông qua ‘tổ hợp gốc’ (root complex) của CPU nhưng vẫn nằm trong phạm vi cục bộ của socket đó.
Tuy nhiên, việc giao tiếp liên CPU (cross-CPU) bắt buộc phải đi qua các đường liên kết UPI giữa hai bộ xử lý Xeon 6. Dòng chip 6787P cung cấp bốn đường liên kết UPI 2.0 với tốc độ 24 GT/s mỗi đường, mang lại băng thông liên socket rất lớn. Mặc dù vậy, lưu lượng dữ liệu giữa một bộ tăng tốc (GPU) trên cụm switch của CPU0 và một card mạng (NIC) trên cụm switch của CPU1 chắc chắn sẽ có độ trễ cao hơn so với việc truyền tải nội bộ trong một switch hoặc trong cùng một socket.
Bản thân các bộ chuyển mạch không được kết nối trực tiếp với nhau. Mọi lưu lượng dữ liệu giữa các switch đều phải định tuyến qua root complex của CPU, vì vậy việc hiểu rõ mối quan hệ tương thích (affinity) giữa các khe cắm GPU, khe cắm NIC, ổ cứng lưu trữ và các socket CPU là cực kỳ quan trọng. Để đơn giản hóa sự phức tạp này cho các doanh nghiệp, Dell cung cấp các cấu hình đã được xác thực và tối ưu hóa cho các dòng bộ tăng tốc phổ biến
Hệ thống cấp nguồn hai phân vùng (Dual-Zone)
Hệ thống cấp nguồn của XE7740 mô phỏng theo cấu trúc tản nhiệt của nó với thiết kế bộ nguồn (PSU) hai phân vùng khá lạ lẫm. Hệ thống hỗ trợ tối đa tám bộ nguồn có thể thay thế nóng (hot-swappable), được chia thành hai vùng: Vùng 1 (Vùng CPU) bao gồm các bộ nguồn PSU 1 và 2, trong khi Vùng 2 (Vùng GPU) chứa các bộ nguồn từ PSU 3 đến PSU 8.

Hệ thống yêu cầu ít nhất một bộ nguồn (PSU) ở mỗi phân vùng để duy trì hoạt động của bộ điều khiển BMC và nguồn dự phòng (standby power). Nếu bất kỳ phân vùng nào bị mất nguồn điện xoay chiều (AC) trong khi hệ thống đang chạy, máy chủ sẽ lập tức tắt nguồn để ngăn ngừa mất mát dữ liệu.
Các phân vùng này phụ thuộc lẫn nhau để vận hành, mặc dù chúng được tách biệt về mặt vật lý và điện năng. Để đạt được sự dự phòng toàn diện, Dell khuyến nghị cấu hình 1+1 ở phân vùng CPU và cấu hình 3+3 ở phân vùng GPU. Điều này có nghĩa là cả tám khoang PSU nên được lắp đầy để đảm bảo hệ thống có khả năng dự phòng lỗi hoàn chỉnh

Dell AIOps, Quản trị và Độ tin cậy cho Doanh nghiệp
Nền tảng PowerEdge của Dell đã tạo dựng được uy tín trong ngành về độ tin cậy và khả năng bảo trì. Các khách hàng doanh nghiệp thường xuyên nhấn mạnh vào những giá trị tương tự: hệ thống PowerEdge được chế tạo để hoạt động bền bỉ, tổ chức hỗ trợ của Dell giải quyết các sự cố nhanh chóng, và các công cụ quản trị của họ đã đạt đến độ chín muồi cũng như được tích hợp rất tốt.
Dòng XE7740 tiếp tục kế thừa truyền thống này, đồng thời Dell đã thực hiện những tiến bộ rõ rệt trong cả việc quản lý phần cứng và bảo mật với thế hệ máy chủ mới này.
iDRAC 10
XE7740 được xuất xưởng với thế hệ tiếp theo iDRAC 10 của Dell, một sự thay đổi diện mạo đáng kể so với iDRAC 9 vốn đã rất mạnh mẽ mà khách hàng của Dell tin dùng trong nhiều năm qua. Được triển khai dưới dạng Mô-đun Điều khiển Bảo mật Trung tâm Dữ liệu (DC-SCM) tuân theo tiêu chuẩn OCP DC-MHS, iDRAC 10 không đơn thuần là một bản cập nhật firmware; nó đại diện cho một nền tảng phần cứng mới. Bộ điều khiển này sở hữu bốn nhân 1 GHz với kiến trúc 64-bit và 2 GB bộ nhớ DDR4 (gấp đôi so với thế hệ trước), mang lại hiệu suất và khả năng phản hồi được cải thiện rõ rệt cho các thao tác quản trị.
Về mặt bảo mật, iDRAC 10 giới thiệu nhiều cải tiến đáng chú ý. Nền tảng này hỗ trợ các chuẩn mã hóa mạnh mẽ hơn trên toàn hệ thống, bao gồm xác thực SHA-384, SHA-512 và mã hóa AES-256 an toàn lượng tử (quantum-safe), nhằm chuẩn bị cho các mối đe dọa mật mã trong kỷ nguyên hậu lượng tử.
Một “vùng bảo mật tích hợp” biệt lập (dedicated integrated security enclave) bên trong chip iDRAC 10 sẽ quản lý các chức năng phục hồi an ninh mạng, bao gồm xác thực cấp thiết bị và công nghệ Root-of-Trust tùy chỉnh của Dell. Công nghệ Root-of-Trust dựa trên phần cứng này đảm bảo rằng tất cả firmware (BIOS, iDRAC và firmware của các linh kiện) đều được xác thực bằng mã hóa trước khi thực thi, giúp chống lại các cuộc tấn công chuỗi cung ứng và giả mạo firmware.
Tính năng Xác minh linh kiện bảo mật (Secured Component Verification) giúp xác nhận rằng các hệ thống xuất xưởng từ nhà máy của Dell đến tay khách hàng với đúng chính xác các linh kiện và cấu hình đã đặt, duy trì tính toàn vẹn từ khâu sản xuất đến khi triển khai. Ngoài ra, firmware iDRAC 10 mới nhất cũng mang đến một giao diện người dùng dạng mô-đun được làm mới, giúp cải thiện trải nghiệm quản trị hàng ngày.
OpenManage Enterprise
Để quản lý số lượng lớn máy chủ (fleet management), phần mềm OpenManage Enterprise (OME) của Dell cung cấp khả năng giám sát tập trung, cập nhật firmware và quản lý cấu hình trên toàn bộ các hệ thống PowerEdge được triển khai.
Một sự bổ sung đáng chú ý gần đây dành cho các hệ thống chuyên dụng cho AI là OME hiện đã hỗ trợ hiển thị trực tiếp các thông số thống kê của GPU và bộ tăng tốc: bao gồm mức tiêu thụ điện năng, nhiệt độ, hiệu suất sử dụng (utilization), số lỗi phát sinh, và nhiều thông số khác mà không cần đến các công cụ riêng biệt từ nhà sản xuất card (như NVIDIA hay AMD).
Đối với các tổ chức đang vận hành hàng chục hoặc hàng trăm nút mạng XE7740 trong một cụm suy luận (inference cluster), mặt phẳng quản trị thống nhất (unified management plane) này là một bước đơn giản hóa đáng kể về mặt vận hành.
Intel Xeon 6
Trung tâm của máy chủ XE7740 là hai bộ xử lý Intel Xeon 6 6787P, dòng chip đầu bảng của hệ sê-ri Xeon 6700P. Được xây dựng trên kiến trúc Granite Rapids sử dụng tiến trình Intel 3nm, chip 6787P cung cấp tới 86 nhân hiệu năng cao (P-cores) với 172 luồng trên mỗi socket, mức tiêu thụ điện năng (TDP) là 350W, xung nhịp cơ bản 2.0 GHz và xung nhịp tăng tốc (turbo) đạt 3.8 GHz.
Điều khiến kiến trúc Granite Rapids trở nên đặc biệt phù hợp cho hạ tầng AI chính là sự kết hợp giữa số lượng nhân cực lớn và hệ thống phụ trợ bộ nhớ (memory subsystem) của nó. Mỗi bộ xử lý 6787P cung cấp 8 kênh bộ nhớ DDR5 với tốc độ lên đến 6400 MT/s. Với một chiếc XE7740 chạy hai socket được lắp đầy 32 thanh RAM (DIMM), hệ thống có thể được cấu hình để đạt tổng dung lượng bộ nhớ hệ thống lên tới 4 TB.

Dung lượng và băng thông bộ nhớ là những yếu tố then chốt đối với các khối lượng công việc AI, đặc biệt là khi áp dụng kỹ thuật đẩy bộ nhớ đệm KV (KV cache offloading) sang bộ phận khác. Khi các mô hình ngôn ngữ lớn tăng chiều dài ngữ cảnh (context length), bộ nhớ đệm KV cũng tăng theo tỷ lệ thuận và có thể tiêu tốn một lượng đáng kể bộ nhớ của bộ tăng tốc (HBM trên GPU).
Việc đẩy một phần bộ nhớ đệm KV sang bộ nhớ hệ thống (RAM) hoặc ổ cứng lưu trữ tốc độ cao giúp bộ nhớ HBM của GPU được sử dụng hiệu quả hơn cho các tính toán đang thực thi, từ đó giảm thời gian phản hồi token đầu tiên (TTFT) trong các cuộc hội thoại nhiều lượt.
Cũng cần lưu ý đến các đơn vị xử lý tensor AMX của Xeon 6, vốn đảm nhiệm một lượng công việc đáng kể ở phía CPU. Các tác vụ này bao gồm tiền xử lý, mã hóa từ ngữ (tokenization) và các tác vụ suy luận hỗn hợp liên quan đến các phép toán ma trận. Điều này trở nên đặc biệt hữu ích với các khung làm việc (framework) suy luận như SGLang, vốn sử dụng CPU để quản lý bộ nhớ đệm KV theo cấu trúc cây Radix (Radix Tree) và lập lịch không độ trễ (Zero Overhead scheduling).
Card mở rộng Intel Gaudi 3: Khả năng suy luận cạnh tranh ở quy mô lớn
Gaudi 3 là bộ tăng tốc AI chủ lực của Intel, được ra mắt vào quý 4 năm 2024. Intel đang định vị dòng bộ tăng tốc này một cách rất quyết liệt; thay vì cạnh tranh trực diện với các bộ tăng tốc huấn luyện trung tâm dữ liệu phân khúc cao cấp nhất, Gaudi 3 được nhắm thẳng vào phân khúc suy luận (inference).

Việc suy luận các mô hình dựa trên kiến trúc Transformer trong tất cả các LLM phổ biến hiện nay về cơ bản đều bị giới hạn bởi bộ nhớ (memory-bound). Trong giai đoạn giải mã (decode phase) của quá trình tạo văn bản tự hồi quy (autoregressive generation), mô hình sẽ tạo ra từng token một, đồng thời phải đọc các trọng số của mô hình và các thực thể trong bộ nhớ đệm KV cho mỗi token được tạo ra. Điểm nghẽn ở đây không nằm ở khả năng tính toán mà nằm ở băng thông bộ nhớ — tức là tốc độ mà bộ tăng tốc có thể truyền dữ liệu từ bộ nhớ HBM vào các nhân tính toán.
Gaudi 3 sở hữu 128 GB bộ nhớ HBM2e với băng thông bộ nhớ lên tới 3.7 TB/s. Về mặt kiến trúc, Gaudi 3 được xây dựng trên tiến trình 5nm của TSMC và sử dụng thiết kế chiplet hai đế (dual-die): hai đế silicon giống hệt nhau được ghép nối bởi một kết nối băng thông cao, xuất hiện dưới dạng một thiết bị thống nhất duy nhất đối với phần mềm.
Khối tính toán được tổ chức thành bốn Lõi Học Sâu (DCOREs), mỗi lõi chứa 2 công cụ nhân ma trận (MMEs), 16 bộ xử lý tensor (TPCs) và 24 MB bộ nhớ đệm SRAM cục bộ. Tổng cộng 96 MB SRAM trên chip cung cấp băng thông nội bộ lên tới 12.8 TB/s. Bộ tăng tốc này cũng tích hợp 14 bộ giải mã đa phương tiện chuyên dụng (H.265, H.264, JPEG, VP9), cho phép tiền xử lý hình ảnh nhanh chóng cho các khối lượng công việc đa phương thức (multi-modal).

Phần lớn các mô hình AI mã nguồn mở tiên tiến (frontier models) được phát hành hiện nay đều được huấn luyện nguyên bản trên định dạng FP8, hoặc là các mô hình lai (hybrid) kết hợp giữa trọng số FP8 (E4M3) và BF16.
Gaudi 3 cung cấp khả năng tăng tốc FP8 nguyên bản cho các định dạng này thông qua 8 Công cụ Nhân Ma trận (MMEs) và 64 Lõi Xử lý Tensor (TPCs), mang lại hiệu suất tính toán FP8 lên tới 1.8 PFlops.

Gaudi 3 cũng tích hợp sẵn công nghệ mạng RDMA qua Ethernet hội tụ (RoCEv2) trực tiếp vào trong silicon, với 24 cổng 200 GbE trên phiên bản OAM (dạng mô-đun).
Mặc dù biến thể card rời PCIe được sử dụng trong máy chủ XE7740 không đưa toàn bộ các cổng này ra ngoài theo cùng một cách, nhưng các phiên bản card rời này vẫn hỗ trợ kết nối cầu (bridging) giữa 4 card với nhau để tăng tốc độ giao tiếp nội bộ giữa chúng.
Hiệu năng và kkiểm thử (Benchmarks)
Cấu hình hệ thống XE7740 thử nghiệm:
- 2 x Bộ xử lý Intel Xeon 6787P (86 nhân, 2.00 GHz)
- 2TB RAM DDR5 (32 x 64GB tốc độ 5200MT/s)
- 4 x Bộ tăng tốc AI Intel Gaudi 3 PCIe với 128GB HBM
- Hệ điều hành: Ubuntu 24.04.5 Server
Hiệu năng phục vụ trực tuyến vLLM Để đánh giá khả năng tính toán của Dell XE7740 chạy chip Gaudi 3, chúng tôi đã kiểm thử hiệu năng phục vụ trực tuyến của vLLM trên nhiều mô hình phổ biến với các kiến trúc, số lượng tham số và định dạng độ chính xác khác nhau. Mỗi mô hình được thử nghiệm qua ba kịch bản tải công việc với số lượng yêu cầu đồng thời tăng dần từ 1 đến 128.
Suy luận LLM bao gồm hai giai đoạn riêng biệt:
- Giai đoạn Prefill (Nạp trước): Xử lý tất cả các token đầu vào song song trước khi tạo ra bất kỳ token đầu ra nào. Đây là thao tác bị giới hạn bởi khả năng tính toán (compute-bound) và tăng tuyến tính theo số lượng token đầu vào.
- Giai đoạn Decode (Giải mã): Tạo ra từng token đầu ra một (tự hồi quy). Mỗi token mới yêu cầu đọc toàn bộ trọng số mô hình từ bộ nhớ nhưng thực hiện rất ít tính toán trên mỗi token — làm cho nó bị giới hạn bởi băng thông bộ nhớ (memory-bandwidth bound).
Hai giai đoạn này gây áp lực lên các phần khác nhau của bộ tăng tốc, vì vậy chúng tôi thử nghiệm ba kịch bản tải để thay đổi sự cân bằng giữa chúng:
- Cân bằng (Equal): (1024 token vào/1024 token ra) đại diện cho các tương tác chat thông thường.
- Nặng về Prefill (Prefill Heavy): (8192 vào/1024 ra) mô phỏng kỹ thuật RAG hoặc tóm tắt văn bản dài, nơi hệ thống phải xử lý ngữ cảnh đầu vào khổng lồ.
- Nặng về Decode (Decode Heavy): (1024 vào/8192 ra) đại diện cho việc tạo nội dung dài, nơi băng thông bộ nhớ duy trì sẽ quyết định thông lượng.
Chúng tôi tập trung vào hai chỉ số chính:
- Tổng thông lượng token (Total token throughput): Đo bằng số token trên giây, thể hiện năng lực phục vụ tổng thể của hệ thống dưới tải trọng.
- Thời gian phản hồi token đầu tiên (TTFT): Đo độ trễ từ khi gửi yêu cầu đến khi nhận được chữ đầu tiên. Vì giai đoạn Prefill phải hoàn tất trước khi phát ra token đầu tiên, TTFT gắn liền trực tiếp với hiệu suất tính toán của bộ tăng tốc.
Lưu ý về kết quả độ chính xác FP8: Mặc dù Gaudi 3 hỗ trợ tăng tốc FP8 nguyên bản (lý thuyết sẽ nhanh hơn BF16), nhưng kết quả FP8 trong bài thử nghiệm này lại thấp hơn BF16. Đây không phải giới hạn phần cứng mà là vấn đề về độ chín muồi của phần mềm trong phiên bản vLLM của Intel mà chúng tôi đã thử nghiệm. Intel hiện có phiên bản vLLM dạng plugin mới (bản beta) hứa hẹn sẽ khắc phục các thách thức về hiệu năng này.
Mô hình Llama 3.1 8B Instruct Đây là mô hình Transformer dạng “dense” từ Meta, nghĩa là mọi tham số đều hoạt động cho mỗi token được tạo ra. Với 8 tỷ tham số, nó là một trong những mô hình mã nguồn mở phổ biến nhất cho các tác vụ hàng ngày như tóm tắt tài liệu ngắn, soạn email, trả lời câu hỏi đơn giản và vận hành chatbot cần tốc độ và hiệu quả chi phí hơn là khả năng suy luận chuyên sâu.
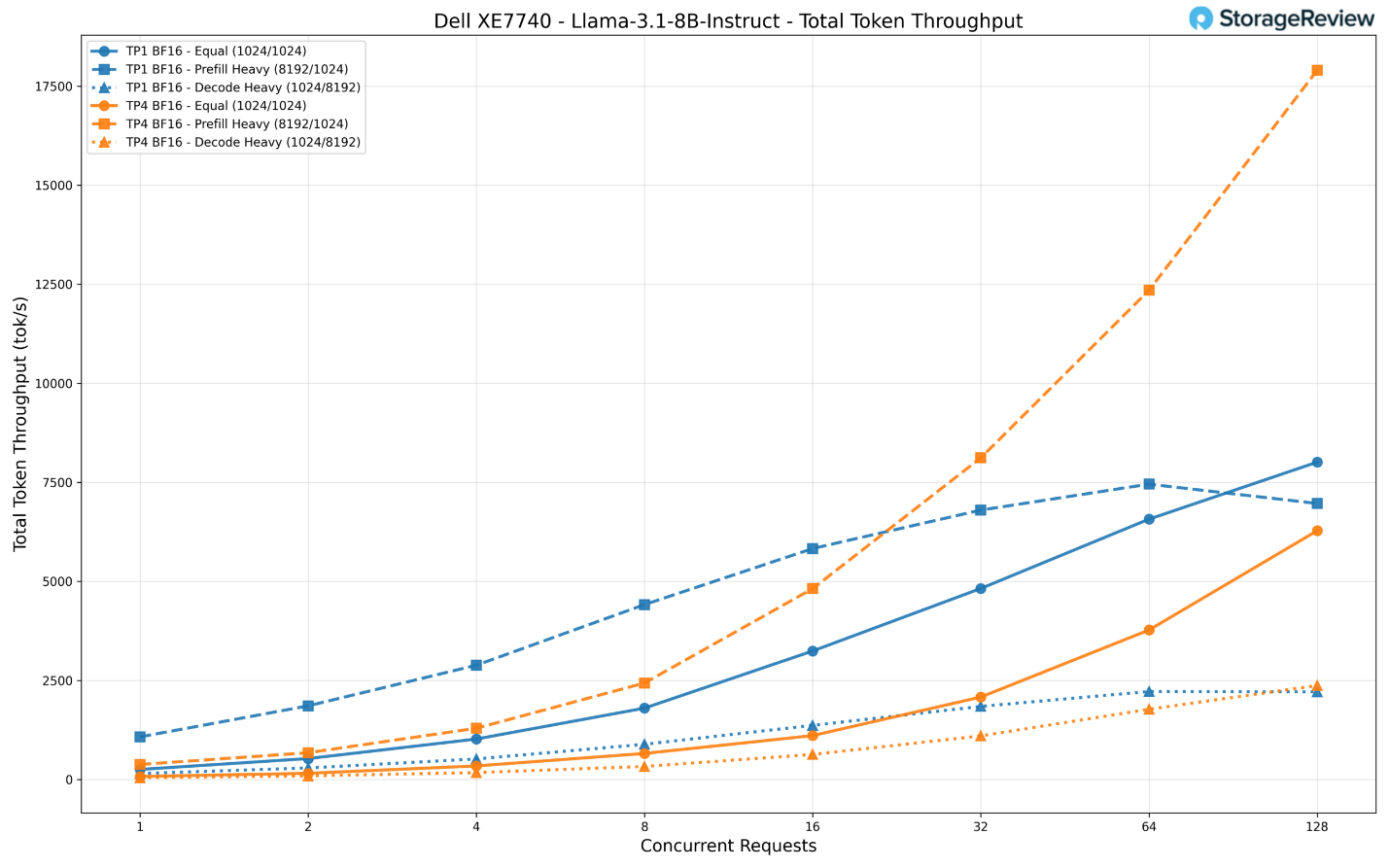
Chúng tôi đã thử nghiệm mô hình này ở cả hai cấu hình: TP1 (sử dụng một bộ tăng tốc duy nhất) và TP4 (sử dụng tất cả bốn bộ tăng tốc Gaudi 3).
Khi chạy ở chế độ TP1, mô hình đạt tổng thông lượng khoảng 8.000 token/giây với 128 yêu cầu đồng thời trong kịch bản tải cân bằng (equal workload), tăng trưởng ổn định từ mức khoảng 250 token/giây khi chỉ có một yêu cầu duy nhất.
Kịch bản nặng về Prefill (nạp dữ liệu đầu vào) cho thấy một mô hình phân bổ thú vị: trong khi TP1 đạt đỉnh ở mức khoảng 7.000 token/giây, thì TP4 đã tăng vọt lên hơn 17.900 token/giây với 128 yêu cầu đồng thời. Điều này cho thấy hệ thống đã tận dụng hiệu quả các bộ tăng tốc bổ sung để xử lý ngữ cảnh đầu vào khổng lồ một cách tối ưu hơn.
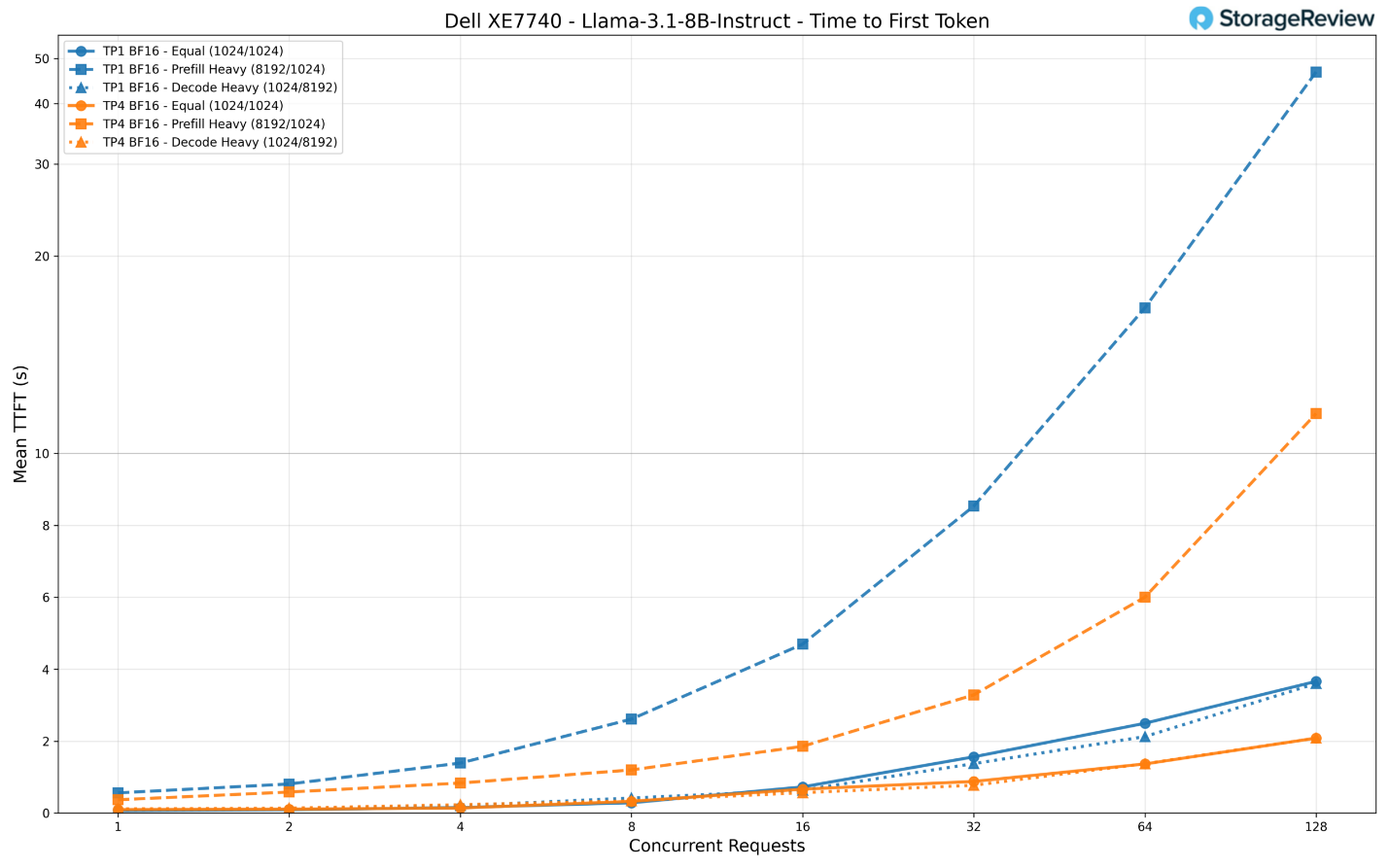
Về độ trễ đối với một người dùng duy nhất, cấu hình TP1 thực tế lại mang lại thời gian phản hồi (TTFT) thấp hơn ở mức yêu cầu thấp (67ms so với 98ms của TP4). Điều này phản ánh chi phí vận hành (overhead) phát sinh khi phải điều phối giữa bốn bộ tăng tốc cho một mô hình vốn dĩ có thể nằm gọn thoải mái trên một card.
Tuy nhiên, khi tải trọng tăng lên, TP4 vượt lên dẫn đầu một cách quyết liệt. Ở mức 128 yêu cầu đồng thời, TP4 duy trì TTFT ở khoảng 2 giây cho các kịch bản tải cân bằng và nặng về giải mã, trong khi TP1 tăng vọt lên lần lượt là 3,7 giây và 6,6 giây. Kịch bản nặng về nạp dữ liệu (prefill-heavy) là nơi khoảng cách trở nên rõ rệt nhất: TP1 đạt tới gần 47 giây TTFT ở 128 yêu cầu, trong khi TP4 giữ mức này ở khoảng 11 giây.
Llama 3.1 70B Instruct Llama 3.1 70B Instruct là mô hình dạng ‘dense’ lớn hơn trong gia đình Llama 3.1 của Meta. Với 70 tỷ tham số, nó mang lại khả năng tuân thủ hướng dẫn và đa ngôn ngữ tốt hơn đáng kể so với biến thể 8B. Các mô hình ở quy mô này rất phù hợp cho các khối lượng công việc dạng đại lý (agentic workloads) chuyên sâu hơn, chẳng hạn như đại diện hỗ trợ khách hàng, trợ lý nghiên cứu đa bước, phân tích tài liệu phức tạp và các tác vụ yêu cầu duy trì ngữ cảnh mạch lạc trong các tương tác dài.
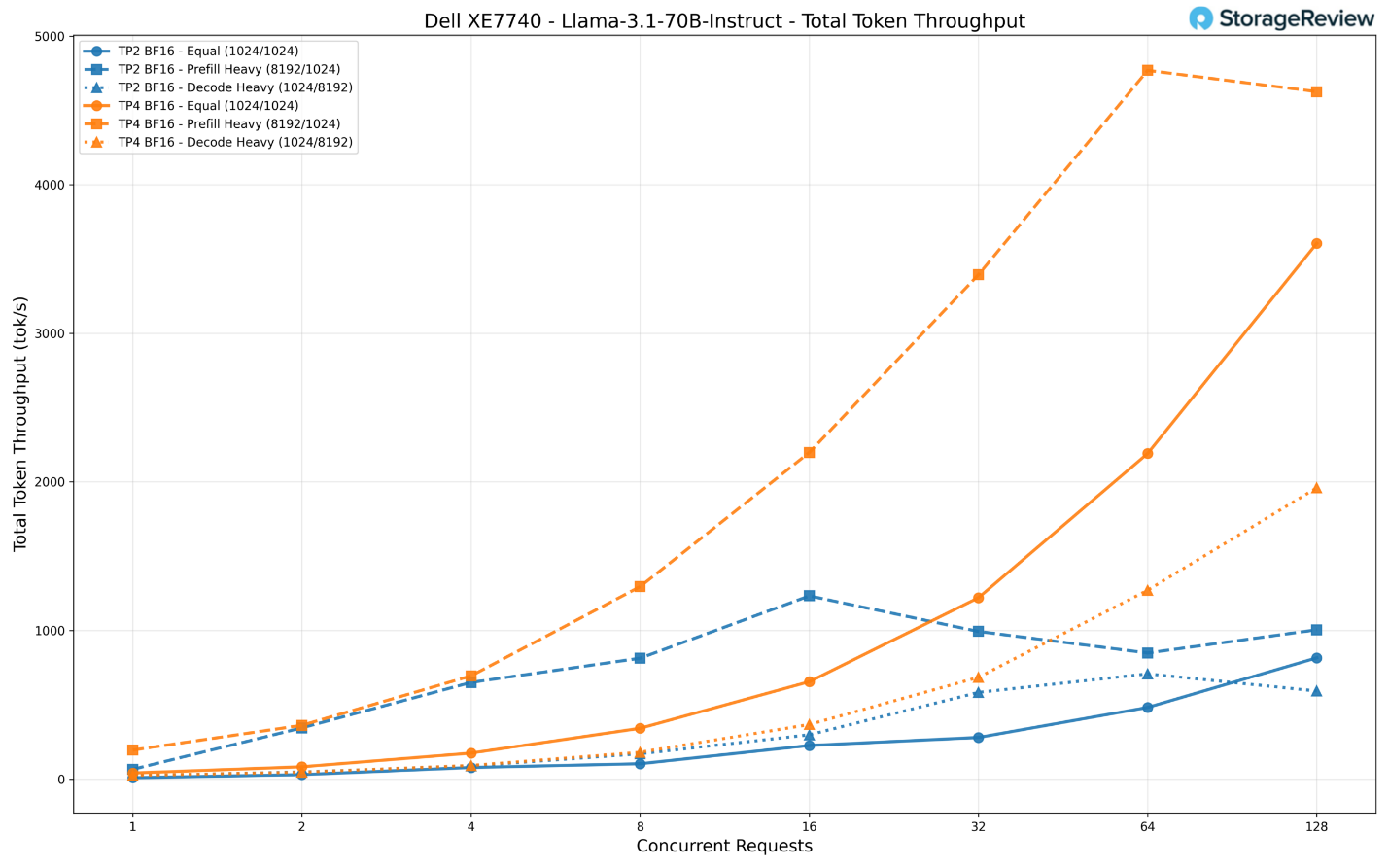
Chúng tôi đã thử nghiệm mô hình này với các cấu hình TP2 (2 bộ tăng tốc) và TP4 (4 bộ tăng tốc). Sự khác biệt về thông lượng giữa hai cấu hình này là cực kỳ lớn.
Ở mức 128 yêu cầu đồng thời, cấu hình TP4 đạt thông lượng khoảng 3.600 token/giây trong kịch bản tải cân bằng và đạt đỉnh gần 4.600 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy). Con số này gấp khoảng 4,4 lần và 4,6 lần so với thông lượng của TP2 (vốn chỉ đạt tối đa khoảng 816 token/giây và 1.005 token/giây tương ứng).
Ngay cả trong kịch bản nặng về giải mã (decode-heavy), TP4 cũng đạt khoảng 1.960 token/giây, so với mức 593 token/giây trên TP2.
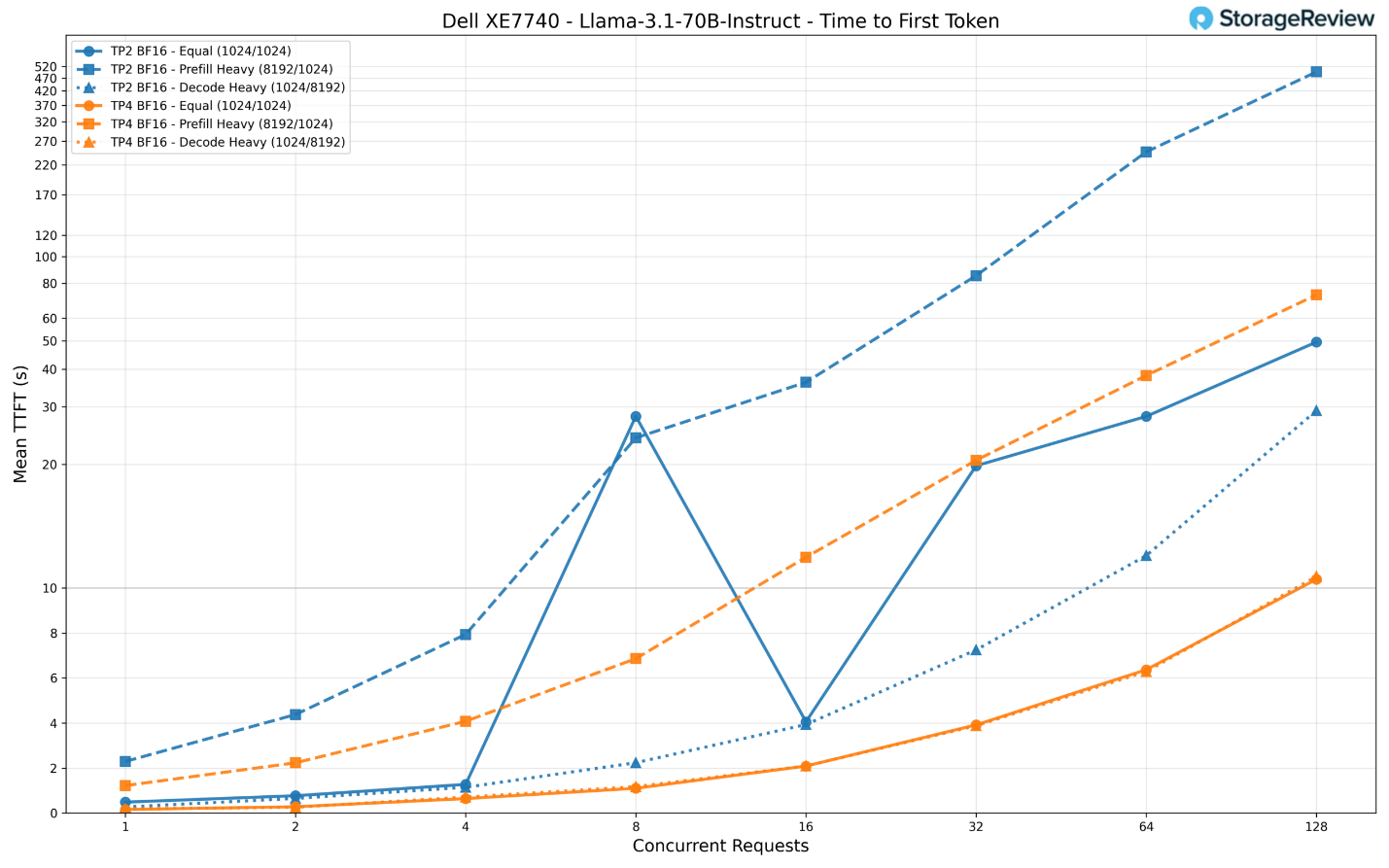
Về thời gian phản hồi (TTFT), cấu hình TP2 (2 card) gặp khó khăn cực độ dưới tải trọng nặng ở kịch bản nạp dữ liệu (prefill-heavy), khi con số này leo thang tới mức kinh khủng là 496 giây (hơn 8 phút) với 128 yêu cầu đồng thời, khiến nó về cơ bản là không thể sử dụng cho các ứng dụng tương tác. TP4 giúp giảm mức này xuống còn khoảng 73 giây. Đối với các kịch bản cân bằng và nặng về giải mã, TP4 duy trì TTFT ở khoảng 10 giây, trong khi TP2 lần lượt chạm mức 50 và 29 giây. Ở mức yêu cầu thấp, TP4 phản hồi token đầu tiên chỉ trong khoảng 160ms, so với 486ms trên TP2.
Qwen3 Coder 30B-A3B Instruct Qwen3 Coder 30B-A3B là một trong những mô hình lập trình phổ biến nhất cho việc triển khai suy luận cục bộ và sử dụng kiến trúc Hỗn hợp các chuyên gia (Mixture-of-Experts – MoE). Khác với các mô hình ‘dense’ (nơi mọi tham số đều tham gia vào mỗi lượt xử lý), các mô hình MoE định tuyến mỗi token qua một nhóm nhỏ các mạng chuyên gia chuyên biệt.
Dòng Qwen3 Coder này duy trì kích thước toàn bộ mô hình là 30 tỷ tham số ở độ chính xác BF16, nhưng chỉ kích hoạt 3 tỷ tham số cho mỗi token được tạo ra. Kiểu kích hoạt thưa thớt này giúp mô hình mang lại chất lượng của một mạng lưới lớn hơn nhiều trong khi chỉ yêu cầu một phần nhỏ sức mạnh tính toán trên mỗi token. Điều này khiến nó cực kỳ hiệu quả trên các phần cứng hỗ trợ tốt việc điều phối dữ liệu (routing overhead). Đối với người dùng cuối, mô hình này rất phù hợp cho hỗ trợ lập trình hàng ngày như tạo mã mẫu (boilerplate), hoàn thiện hàm, giải thích mã nguồn và viết kiểm thử đơn vị (unit tests).
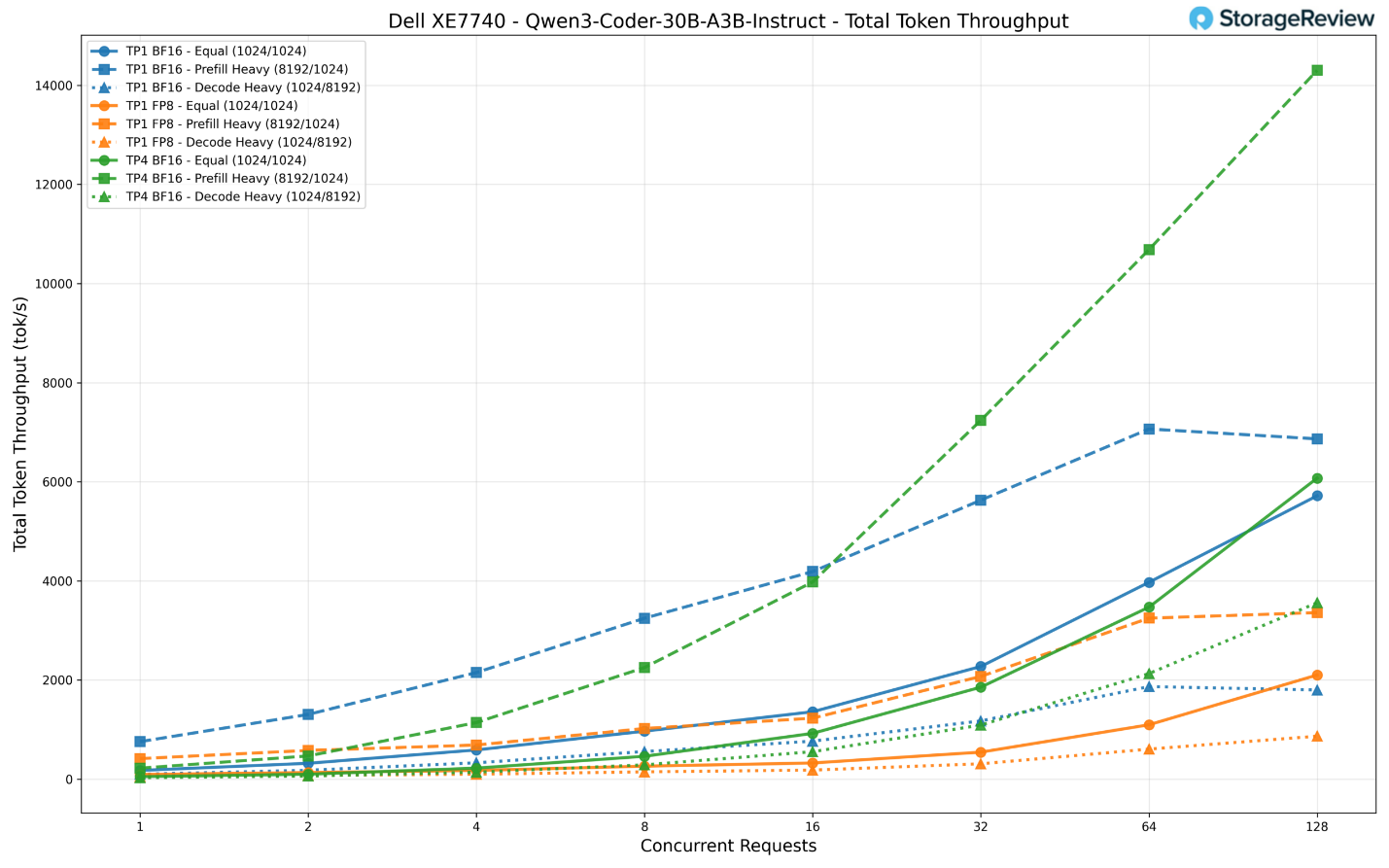
Chúng tôi đã thử nghiệm ba cấu hình: TP1 BF16, TP1 FP8, và TP4 BF16. Ở mức 128 yêu cầu đồng thời, cấu hình TP4 BF16 dẫn đầu nhóm với thông lượng khoảng 14.300 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy) — đây cũng là con số thông lượng cao nhất mà chúng tôi ghi nhận được trên tất cả các mô hình trong bộ thử nghiệm này.
Tiếp theo là TP1 BF16 với khoảng 6.900 token/giây trong cùng kịch bản, trong khi TP1 FP8 tụt lại phía sau ở mức khoảng 3.360 token/giây. Trong kịch bản tải cân bằng (equal workload), khoảng cách có phần hẹp lại với TP4 đạt 6.073 token/giây, TP1 BF16 đạt 5.718 token/giây và TP1 FP8 đạt 2.101 token/giây.
Như đã thảo luận trong phần lưu ý về FP8 ở trên, các con số thấp hơn của FP8 ở đây phản ánh tình trạng hiện tại của phiên bản vLLM do Intel phát triển hơn là do nghẽn cổ chai về phần cứng.
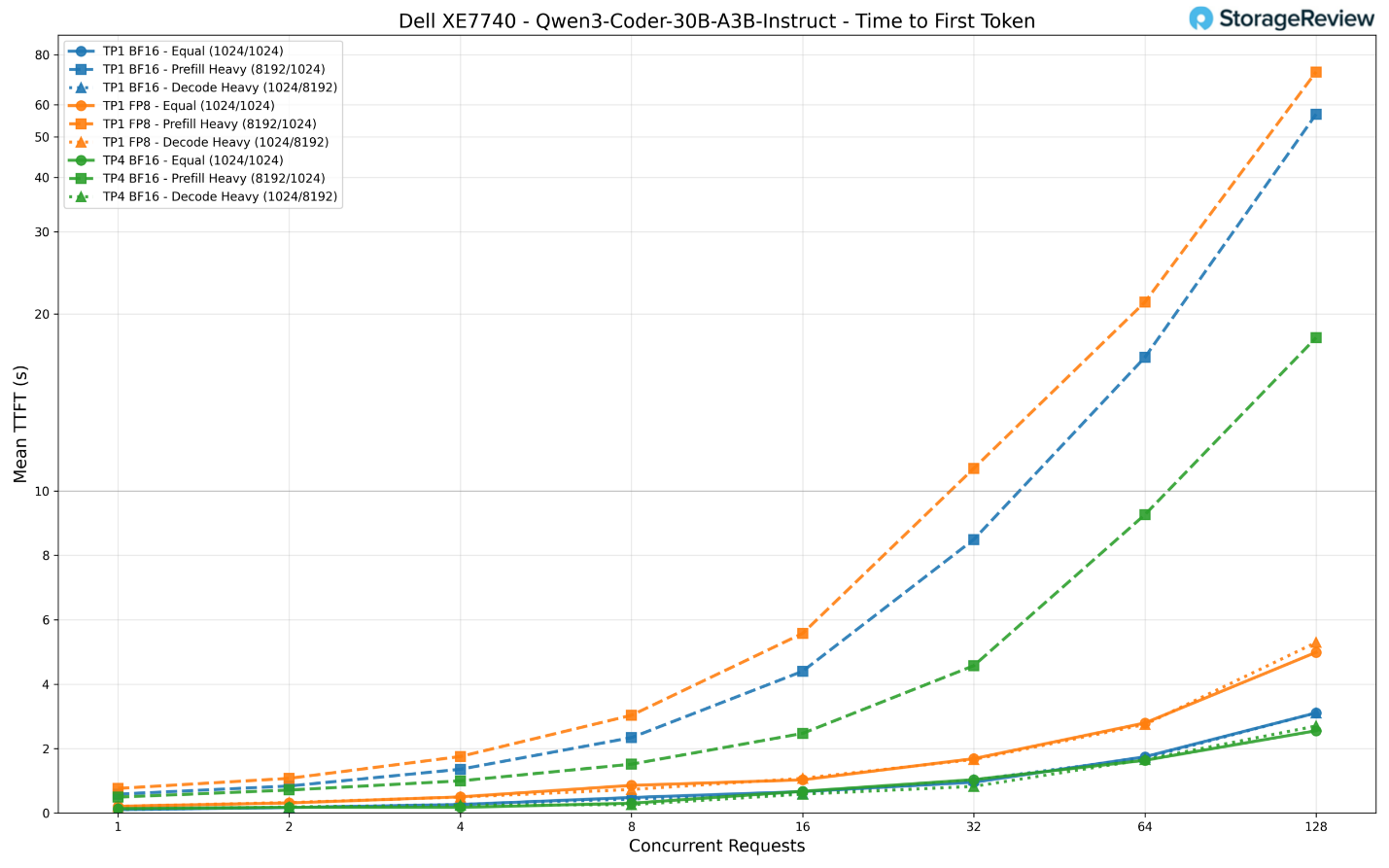
Chỉ số TTFT (thời gian phản hồi đầu tiên) được duy trì ở mức thấp nhờ vào kiểu kích hoạt thưa thớt (sparse activation). Cấu hình TP4 BF16 mang lại độ trễ token đầu tiên khoảng 140ms khi chỉ có một người dùng và giữ ở mức khoảng 2,6 giây với 128 yêu cầu đồng thời trong kịch bản tải cân bằng.
TP1 BF16 có kết quả tương đương ở mức yêu cầu thấp (106ms) nhưng tăng lên 3,1 giây khi chịu tải tối đa. Kịch bản nặng về nạp dữ liệu (prefill-heavy) một lần nữa phân hóa rõ rệt các cấu hình: TP4 đạt khoảng 18 giây với 128 yêu cầu, trong khi TP1 BF16 chạm mức 57 giây và TP1 FP8 kéo dài tới 72 giây.
Qwen3 235B-A22B Thinking Là mô hình lớn nhất trong bộ thử nghiệm của chúng tôi, Qwen3 235B-A22B Thinking là một mô hình suy luận MoE khổng lồ với tổng cộng 235 tỷ tham số và 22 tỷ tham số kích hoạt cho mỗi token.
Vượt xa quy mô thông thường, mô hình này tích hợp sẵn khả năng suy luận chuỗi suy nghĩ (Chain-of-Thought – CoT), cho phép nó chia nhỏ các vấn đề phức tạp theo từng bước trước khi đưa ra câu trả lời cuối cùng (đổi lại là tốn nhiều token giải mã hơn). Điều này khiến nó đặc biệt phù hợp cho các nhiệm vụ khó khăn nhất: tạo mã nguồn nâng cao và gỡ lỗi, giải toán, suy luận logic đa bước và các quy trình đại lý (agentic) phức tạp nơi độ chính xác quan trọng hơn tốc độ thuần túy. Mô hình này bắt buộc phải chạy trên cấu hình TP4 (4 card) và chúng tôi đã thử nghiệm nó ở cả hai độ chính xác BF16 và FP8.
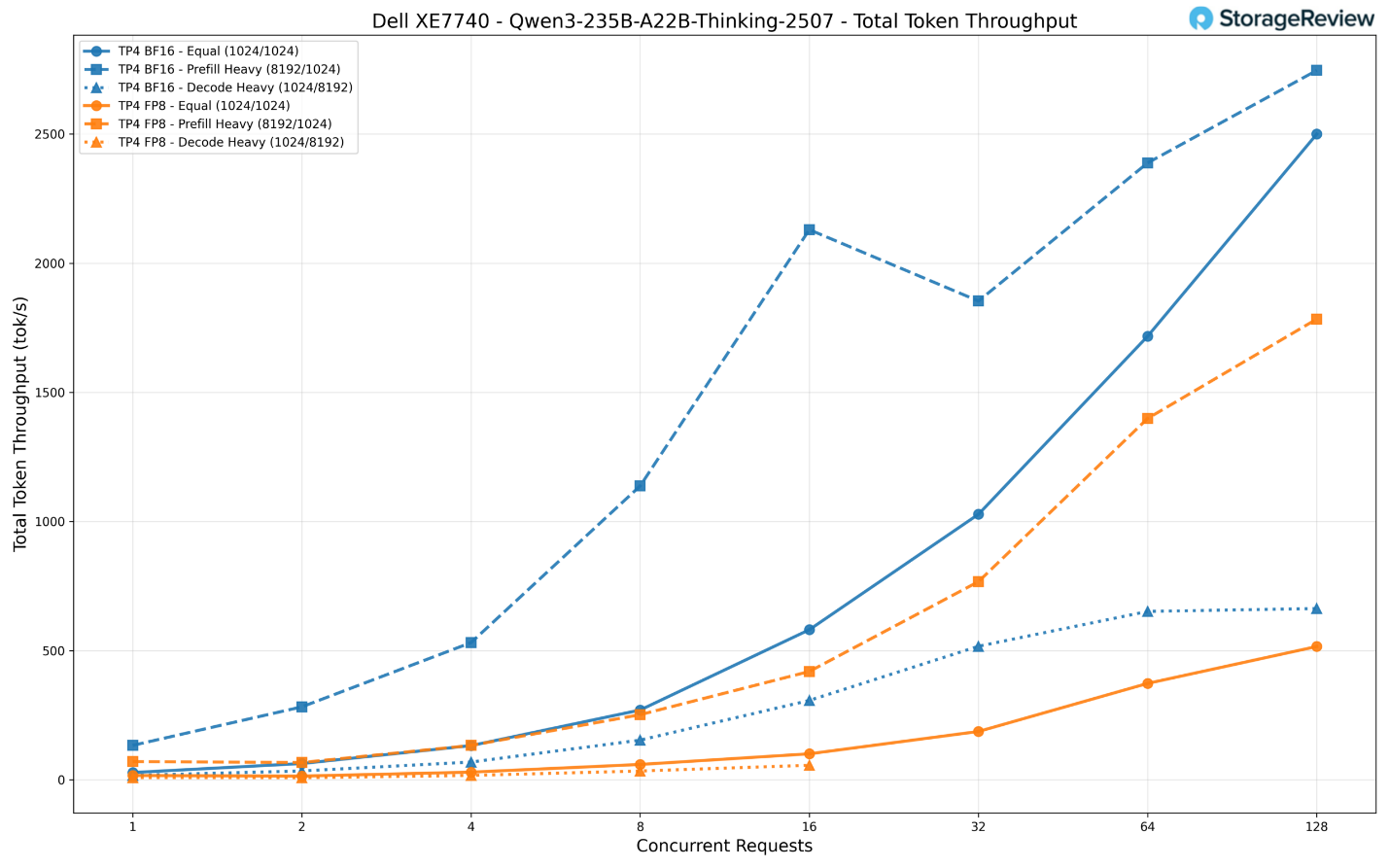
BF16 rõ ràng vượt trội hơn FP8 trên mọi phương diện. Ở mức 128 yêu cầu đồng thời, định dạng BF16 đạt thông lượng xấp xỉ 2.750 token/giây trong kịch bản nặng về nạp dữ liệu (prefill-heavy) và 2.500 token/giây trong kịch bản cân bằng.
Trong khi đó, định dạng FP8 chỉ đạt lần lượt khoảng 1.784 token/giây và 516 token/giây. Biến thể FP8 thậm chí còn gặp hiện tượng quá hạn thời gian (timeout) trong kịch bản nặng về giải mã (decode-heavy) ở các mức yêu cầu đồng thời cao (từ 32 yêu cầu trở lên).
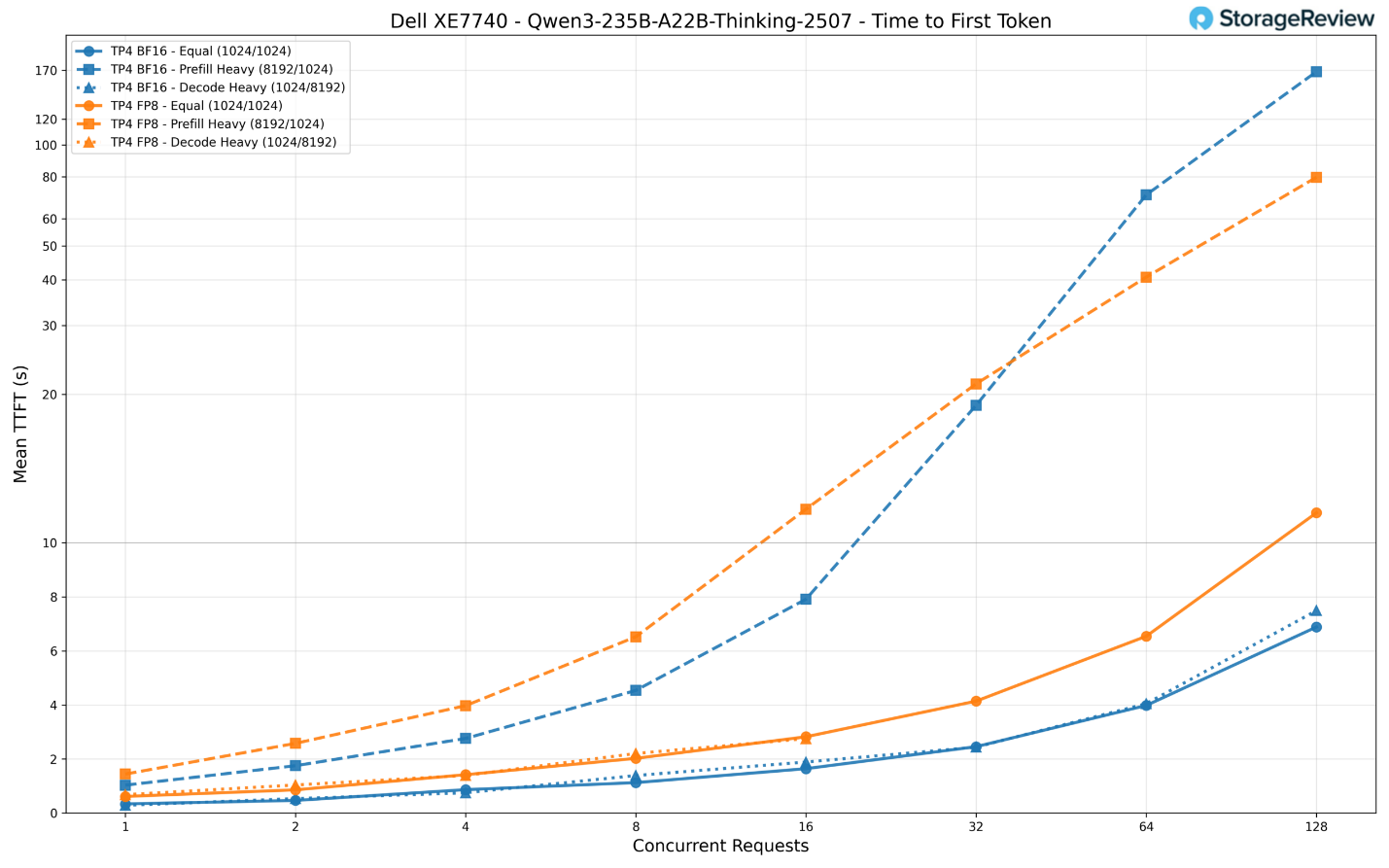
Về thời gian phản hồi (TTFT), định dạng BF16 bắt đầu ở mức khoảng 340ms cho một yêu cầu cân bằng duy nhất và tăng lên xấp xỉ 6,9 giây với 128 yêu cầu đồng thời. Đây là mức phản hồi khá tốt cho một mô hình ở quy mô khổng lồ này.
Định dạng FP8 chậm hơn khoảng 2 lần trong suốt quá trình thử nghiệm, bắt đầu ở mức 615ms và chạm ngưỡng 11,2 giây khi chịu tải tối đa. Kịch bản nặng về nạp dữ liệu (prefill-heavy) là thử thách khắc nghiệt nhất, với BF16 tăng lên 168 giây và FP8 lên 80 giây ở mức 128 yêu cầu.
Giải pháp này dành cho ai? Nhu cầu về suy luận AI (Inference) không hề có dấu hiệu chậm lại. Dù các tổ chức đang triển khai mô hình nội bộ để hỗ trợ các đội ngũ lập trình viên, tích hợp AI vào các sản phẩm dành cho khách hàng, hay thiết lập các quy trình tự động hóa chạy 24/7, yêu cầu về năng lực tính toán vẫn liên tục tăng cao.
Và đi kèm với nhu cầu đó là một “nút thắt cổ chai” quen thuộc: Khâu mua sắm. Thời gian chờ đợi (lead times) để có được các bộ tăng tốc phổ biến nhất (như của NVIDIA) có thể kéo dài hàng tháng trời, làm đình trệ các dự án vốn đã được cấp vốn và bố trí nhân sự.
Đoạn kết này nhấn mạnh vào tính sẵn có, sự linh hoạt và giá trị thực tiễn của Dell PowerEdge XE7740 trong bối cảnh thị trường AI đang cực kỳ khan hiếm phần cứng.
Bản dịch:
“Máy chủ XE7740, khi được cấu hình với Intel Gaudi 3, đã giải quyết trực tiếp các hạn chế về nguồn cung. Các bộ tăng tốc Gaudi 3 hiện đã sẵn hàng, và Intel cung cấp các mẫu triển khai đã được xác thực để các đội ngũ kỹ thuật có thể đi từ khâu mở hộp đến phục vụ suy luận chỉ trong vài giờ.
Dell còn hạ thấp rào cản hơn nữa bằng các chương trình ‘dùng thử trước khi mua’ (try-and-buy), cho phép đặt hệ thống XE7740 trực tiếp vào môi trường của bạn. Điều này giúp bạn kiểm chứng hiệu năng thực tế dựa trên khối lượng công việc, dữ liệu và hạ tầng hiện có trước khi quyết định triển khai chính thức. Sự kết hợp giữa khả năng cung ứng tức thì, thời gian tạo ra giá trị nhanh chóng và đánh giá rủi ro thấp khiến cấu hình Gaudi 3 trở nên đặc biệt hấp dẫn đối với các tổ chức cần năng lực suy luận ngay hôm nay và không thể chờ đợi trong các hàng đợi cấp phát linh kiện.
Tuy nhiên, XE7740 không phải là nền tảng chỉ dành cho một loại bộ tăng tốc duy nhất. Với cam kết của Dell về sự đa dạng hóa silicon, cùng một nền tảng này có thể đi kèm với nhiều tùy chọn bộ tăng tốc phổ biến nhất trên thị trường, và lựa chọn đúng đắn hoàn toàn phụ thuộc vào khối lượng công việc. Ví dụ, các luồng xử lý video là sự lựa chọn tự nhiên cho NVIDIA L4, và XE7740 có thể trang bị tới 16 GPU L4 cùng với 8 khe cắm NIC PCIe Gen5 x16 để tạo nên một hệ thống truyền phát và chuyển mã video không có đối thủ. Các tổ chức chạy hỗn hợp các khối lượng công việc AI giữa các phòng ban có thể tiêu chuẩn hóa trên khung máy (chassis) XE7740 và chỉ cần thay đổi cấu hình bộ tăng tốc cho phù hợp với từng nhiệm vụ, giúp đơn giản hóa việc quản lý đội ngũ máy chủ trong khi vẫn tối ưu hóa tính toán cho từng tác vụ cụ thể.
Kết luận Dell PowerEdge XE7740 được thiết kế cho thực tế suy luận của doanh nghiệp. Thiết kế nhiệt hai vùng, sơ đồ PCIe có cấu trúc, kiến trúc bộ nhớ băng thông cao và khả năng kết nối mạng mở rộng tạo nên một hệ thống được xây dựng cho các khối lượng công việc sản xuất bền bỉ. Đây không phải là những lựa chọn thiết kế ngẫu nhiên; chúng phản ánh một mô hình hạ tầng nơi việc suy luận chạy liên tục, mở rộng theo dự đoán và tích hợp sạch sẽ vào các hoạt động trung tâm dữ liệu hiện có.
Trong bài đánh giá này, Intel Gaudi 3 đã chứng minh rằng XE7740 mang lại khả năng suy luận mạnh mẽ ngay hôm nay trên cả kiến trúc ‘dense’ và MoE, với khả năng mở rộng dự đoán được và thông lượng bị giới hạn bởi bộ nhớ (memory-bound throughput) rất ấn tượng. Các tối ưu hóa phần mềm sẽ tiếp tục được cải thiện, nhưng nền tảng kiến trúc của hệ thống này đã thực sự vững chắc.

Quan trọng hơn cả, PowerEdge XE7740 đã thiết lập một mô hình chuẩn mực và bền vững cho hạ tầng AI doanh nghiệp. Các tổ chức giờ đây có thể chuẩn hóa hệ thống dựa trên một khung máy (chassis), quy trình quản lý và mô hình triển khai đồng nhất, trong khi vẫn có thể linh hoạt thay đổi chiến lược sử dụng bộ tăng tốc (GPU/Accelerators) theo thời gian.
Khi các mô hình AI ngày càng lớn mạnh, khối lượng công việc trở nên đa dạng và quá trình suy luận (inference) dần trở thành một phần cốt lõi trong vận hành kinh doanh, thì nhu cầu về một hạ tầng ổn định và có khả năng thích ứng cao sẽ ngày càng gia tăng. PowerEdge XE7740 được ra đời để đón đầu xu thế đó. Nó mang lại sự cân bằng về kiến trúc, sự tối ưu trong vận hành và không gian mở rộng cần thiết để đưa AI doanh nghiệp từ giai đoạn “áp dụng nhanh chóng” sang giai đoạn “tích hợp dài hạn”.
__________________________________________________
📞 Liên hệ Megacore để được tư vấn cấu hình phù hợp và giải pháp hạ tầng cho doanh nghiệp – hoàn toàn miễn phí
🌐 Website: megacore.net
📧 Email: [email protected]
📲 Hotline: 0345 888 868
Cảm ơn bạn đã tin tưởng và lựa chọn sản phẩm của Megacore! Chúng tôi cam kết mang đến cho bạn những sản phẩm chất lượng và dịch vụ tốt nhất!



